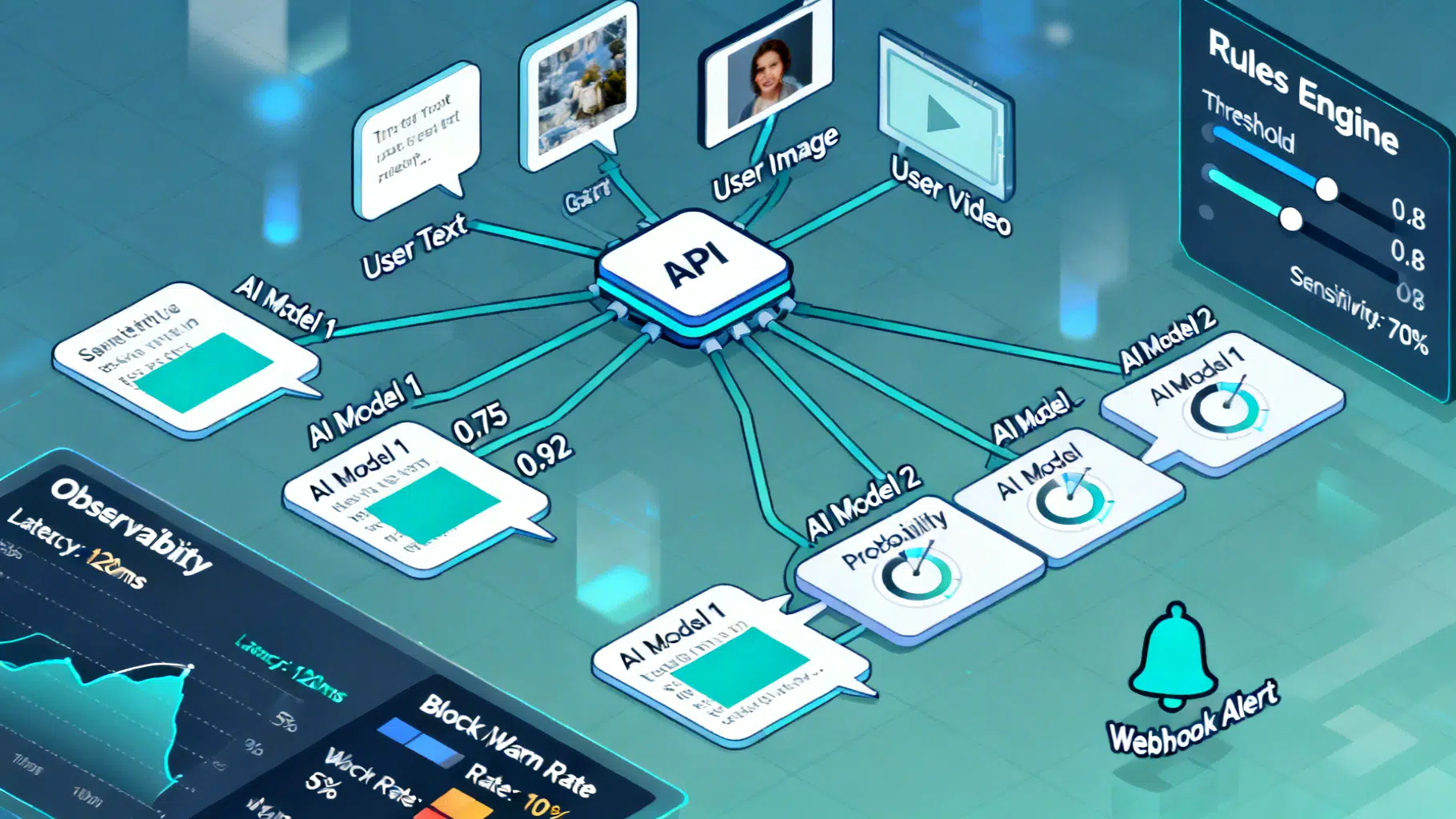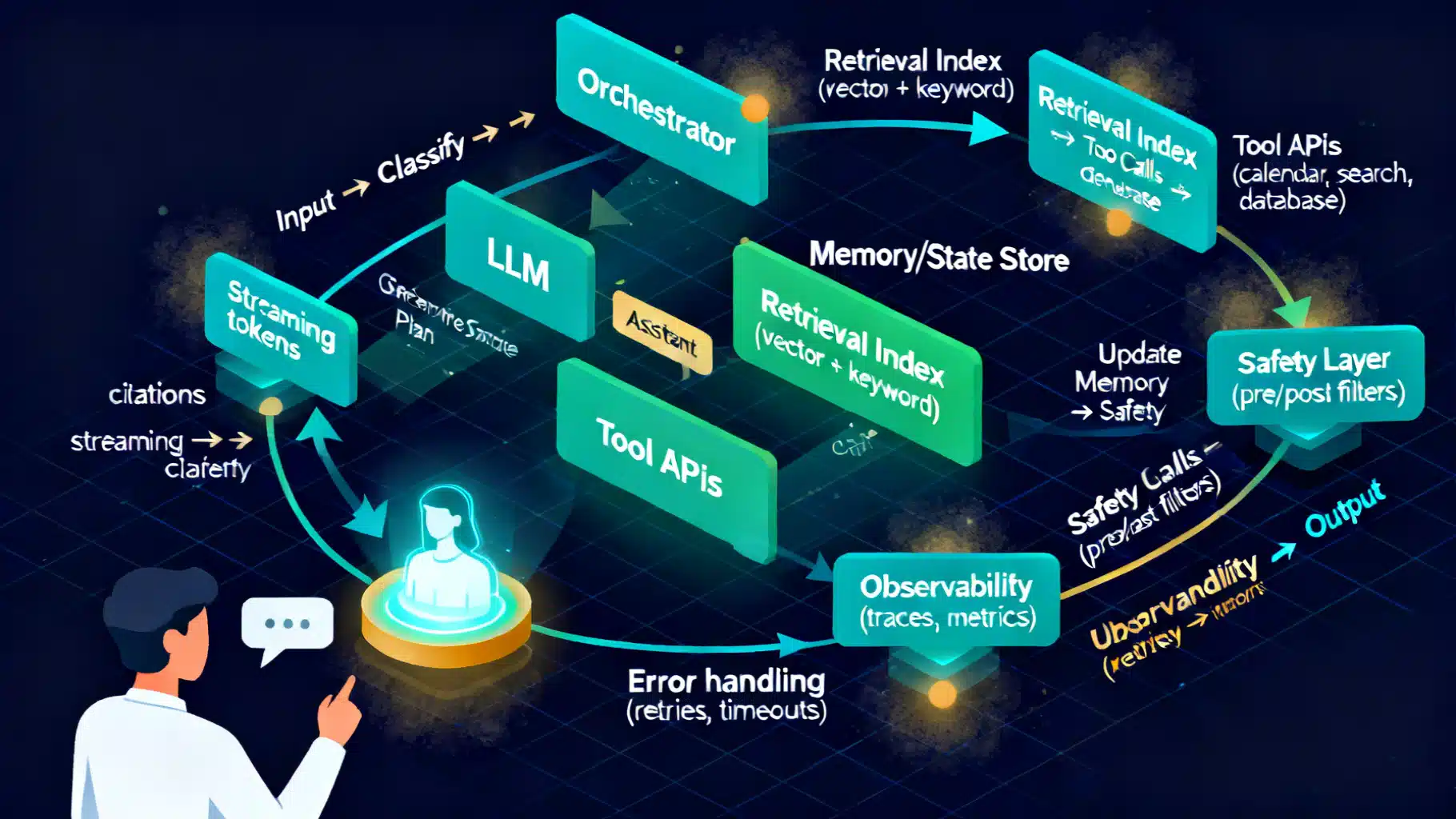
Designing Robust Multi‑Turn Conversational AI: Architecture, Memory, and Evaluation
A practical guide to multi‑turn conversational AI: architecture, memory, grounding, safety, and evaluation patterns for reliable, scalable assistants.
ASOasis
Read More
7 min