Advanced Chunking Strategies for Retrieval‑Augmented Generation
A practical guide to advanced chunking in RAG: semantic and structure-aware methods, parent–child indexing, query-driven expansion, and evaluation tips.
Image used for representation purposes only.
Overview
Retrieval-Augmented Generation (RAG) lives or dies on chunking—the way you split and package source material before embedding, indexing, and retrieving it. Naive, fixed-size windows often fracture meaning, bury crucial context, and bloat latency and cost. Advanced chunking treats documents as structured, semantic objects and adapts to query intent, domain conventions, and production constraints. This article distills practical strategies, algorithms, and evaluation tactics you can apply today.
Why Chunking Matters
RAG answers improve when the retrieved passages actually contain the needed facts, definitions, or procedures. Chunking is the control knob for:
- Recall vs. precision: Larger chunks increase recall of cross-sentence evidence but add noise. Smaller chunks sharpen precision but risk losing context.
- Latency and cost: More, smaller chunks create larger indexes and more candidates to rerank; very large chunks inflate prompt tokens.
- Hallucination defense: Well-formed boundaries preserve local coherence and reduce spurious correlations.
Where Naive Chunking Fails
- Boundary fractures: Splitting mid-paragraph, mid-table, or mid-code-block separates definitions from examples.
- Context dilution: Megachunks drag in unrelated sections, confusing the generator and the reranker.
- Sparse signals: Character-based cuts ignore headings, captions, and citations that anchor meaning.
- Retrieval mismatch: Embeddings for flat windows miss domain cues (e.g., function scopes, legal clauses).
A Quick Refresher on the RAG Loop
- Ingest: Parse documents, extract structure and metadata.
- Chunk: Segment into retrieval units; enrich with metadata.
- Embed: Create vector representations at appropriate granularity.
- Index: Vector (HNSW/IVF) often hybridized with keyword/BM25.
- Retrieve: Candidate generation + reranking.
- Compose: Assemble final context windows under model token budgets.
- Generate: Prompt LLM with context; optionally cite.
Advanced Chunking Strategies
1) Semantic Boundary Detection
Detect section shifts where topical cohesion dips.
Approaches:
- Similarity deltas: Embed consecutive sentences; insert a boundary where cosine similarity drops sharply.
- Topic segmentation: Algorithms like TextTiling-style lexical cohesion or modern transformer-based classifiers trained to predict section starts.
- LLM-guided split/merge: Use a small model to propose paragraph merges or splits by intent (definition, procedure, example, caveat).
Example (Python-ish) to place boundaries with similarity deltas and merge into token-budgeted chunks:
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer("all-MiniLM-L6-v2")
def semantic_chunks(sentences, max_tokens=600, min_tokens=200, overlap_tokens=120, toklen=lambda s: len(s.split())):
embs = model.encode(sentences, normalize_embeddings=True)
# Compute similarity deltas between adjacent sentences
sims = np.sum(embs[:-1] * embs[1:], axis=1)
# Threshold via z-score
mu, sigma = np.mean(sims), np.std(sims) + 1e-6
cut_idx = set(np.where((mu - sims) / sigma > 1.5)[0] + 1)
chunks, cur, cur_tokens = [], [], 0
for i, s in enumerate(sentences):
cur.append(s)
cur_tokens += toklen(s)
if (i + 1 in cut_idx and cur_tokens >= min_tokens) or cur_tokens >= max_tokens:
chunks.append(" ".join(cur))
# create overlap by carrying tail
tail = []
t = 0
for r in reversed(cur):
if t + toklen(r) > overlap_tokens: break
tail.insert(0, r); t += toklen(r)
cur, cur_tokens = tail[:], sum(toklen(x) for x in tail)
if cur:
chunks.append(" ".join(cur))
return chunks
2) Structure-Aware Chunking
Honor the document’s native structure so chunks are semantically contiguous:
- HTML/Markdown: Split at H1–H4 headings; keep lists, code fences, and tables intact. Preserve the heading trail as metadata (doc > section > subsection).
- PDFs: Use layout analysis to keep columns, captions with figures, and table regions together.
- Code: Build chunks by Abstract Syntax Tree (AST) units—function, class, docstring, tests—rather than raw lines.
- Spreadsheets/tables: Row-wise or header+column slices; include the header row in every chunk.
3) Hybrid Sliding Windows with Semantic Anchors
Combine windowing with anchors like headings, “Summary”, “Conclusion”, or domain markers (“RFC:”, “Theorem”, “Proof”). Slide a token window but only finalize a chunk if it starts at, or includes, an anchor. This mitigates mid-thought starts while preserving coverage.
4) Parent–Child Indexing and Passage Expansion
- Children: Small, high-precision units (sentence or short paragraph) for initial retrieval.
- Parents: Larger context (section-level) assembled only for the final prompt.
Workflow: retrieve top-N children by vector/BM25 → map to their parents → deduplicate and rerank parents → assemble with light overlap. This balances precision with context breadth.
5) Query-Aware Dynamic Chunking
At retrieval time, locate anchors mentioned in the query (e.g., “figure 3”, code symbol, clause number) and expand a symmetric window around them to fit the token budget. When the query indicates a procedure (“how to…”, “steps”), bias expansion to include ordered lists and examples.
6) Graph- and Link-Aware Chunking
Exploit hyperlinks, citations, and cross-references. Build chunks that co-locate a statement with its cited basis or link closely connected nodes into a small neighborhood. During retrieval, allow lightweight neighborhood expansion (k-hop ≤ 1) when confidence is low.
7) Multimodal and Structured Artifacts
- Tables: Chunk by row groups or logical slices (header + column). Store a normalized CSV/JSON rendering alongside rendered text to keep structure.
- Figures: Bind captions and alt-text to images; include bounding-box metadata from OCR so you can expand locally when users ask about “the left panel”.
- Forms and logs: Group by session/transaction or time windows rather than fixed sizes.
How Big Should Chunks Be?
Rule of thumb: target chunk size ≈ 3–5× your typical answer span, with 20–30% overlap to protect cross-boundary facts.
Heuristics by domain:
- Expository tech docs: parent 400–900 tokens; child 60–160 tokens.
- Code: parent = one function/class (or ≤ 300–500 tokens); child = signature + docstring + first N lines.
- Legal/contracts: parent = clause/subclause with definitions; child = sentence-level with citation IDs.
- Scientific papers: parent = subsection; child = claim/evidence pairs (sentence + reference bracket).
Token-based sizing adapts across languages better than character counts. Calibrate with your tokenizer because 500 “tokens” can mean very different characters across languages.
Overlap and Stride Tuning
Overlap protects coherence but increases redundancy. Start with:
- overlap_tokens = floor(0.25 × chunk_tokens)
- stride = chunk_tokens − overlap_tokens
Make overlap adaptive: increase near detected boundaries (e.g., around tables, code blocks), decrease within long homogeneous paragraphs. Ensure no sentence is split: expand to include the nearest sentence boundary.
Metadata Enrichment (It’s Part of Chunking)
Attach fields that improve retrieval and reranking:
- heading_path: [“Guide”, “Installation”, “Linux”]
- doc_id, page, figure/table ids
- section_type: definition | example | steps | caveat | api_ref
- timestamps/versions (for time-aware answers)
- entities and symbols (NER, code symbols)
Index some metadata for hybrid search (keyword/BM25) and keep others only for reranking and context ordering.
Indexing and Retrieval Patterns That Complement Chunking
- Hybrid search: Vector + BM25/keyword to catch rare terms, symbols, and IDs.
- Diversification: Use MMR or clustering on child passages to avoid near-duplicates from the same section.
- Field boosts: Prefer matches in titles, headings, and captions.
- Reranking: A cross-encoder reranker over child passages before parent assembly dramatically improves precision.
Context Assembly and Coherence
After retrieval:
- Map children to parents; deduplicate by section.
- Sort by a blend of (rerank score, distance to anchor, document order).
- De-duplicate sentences across parents.
- Respect model token budget and stop early if marginal gain falls below threshold.
Evaluating Chunking: What to Measure
Build a harness that can swap chunkers and keep the rest constant. Measure:
- Chunk Recall@k: % of questions where any gold-supporting sentence appears in the retrieved set.
- nDCG / MRR on retrieval.
- End-task: EM/F1 or graded answer quality.
- Hallucination rate: proportion of claims unsupported by retrieved text.
- Cost/latency: ingestion time, index size, retrieval and rerank latency, prompt tokens.
Generate synthetic QA pairs by sampling spans and prompting a small model to write questions whose answers reside within those spans; keep the “gold span” for evaluation.
Minimal scaffold for ablation:
from typing import Callable
class Chunker:
def __init__(self, fn: Callable[[str], list[str]], name: str):
self.fn, self.name = fn, name
# run_pipeline takes chunker -> (retrieval_metrics, answer_metrics, costs)
def compare(chunkers, corpus, queries):
results = []
for ch in chunkers:
idx = build_index(corpus, ch.fn) # same embed, same index params
metrics = run_pipeline(idx, queries)
results.append((ch.name, metrics))
return sorted(results, key=lambda x: x[1]["answer_f1"], reverse=True)
Domain Playbooks
- Codebases: Chunk by AST; include imports and called symbols in metadata. For cross-file APIs, parent = module or class, children = functions and docstrings.
- Legal: Respect clause hierarchy; duplicate key definitions into dependent clauses via metadata references to improve recall without bloating chunks.
- Support tickets/Logs: Session or issue ID as parent; children by event windows (e.g., 5–15 minutes) to preserve causal order.
- BI/Table QA: Children are row groups keyed by dimension values; parents are slices (header + selected columns). Keep numeric types in a structured store for precise filtering before generation.
Common Anti-Patterns (and Fixes)
- Flat 1,000-character windows: Switch to token-aware, sentence-aligned boundaries with structure preservation.
- Document-level embeddings only: Add child passages for initial retrieval; use parents for assembly.
- Zero overlap: Introduce at least 15–30% overlap or sentence-carry to protect cross-boundary facts.
- Ignoring tables/images: Bind captions and headers; keep structural surrogates (CSV/JSON) for reranking.
- One-size-fits-all: Tune per corpus; code ≠ contracts ≠ blog posts.
Production Considerations
- Versioning: Store chunker version and embedding model version; allow backfills without downtime via dual-write indexes.
- Caching: Cache query → top-k children and assembled parents; invalidate on doc updates by doc_id.
- Cold start: Precompute popular query anchors and warm caches; use BM25 fallback during embedding backfills.
- Deduplication: Hash normalized sentences to prune near-duplicates across mirrors/releases.
- Monitoring: Track retrieval coverage (gold span presence), answer quality, and drift per domain.
- Cost control: Estimate index size = (#children × vector_bytes); prune with recency or doc priority tiers.
A Practical Checklist
- Sentence-aligned, token-aware splitting with adaptive overlap
- Structure-aware segmentation (headings, code blocks, tables)
- Parent–child indexing and reranking
- Query-aware dynamic expansion around anchors
- Rich metadata (heading_path, entity/symbol IDs, section_type)
- Hybrid search with diversification
- Automated ablation harness and golden-span evaluation
- Monitoring, versioning, and cache strategy
Conclusion
Advanced chunking reframes RAG from “split every N characters” to “preserve meaning and retrieve exactly what matters.” By combining semantic boundaries, structure awareness, parent–child indexing, and query-driven expansion—then validating with a rigorous harness—you get higher recall with tighter prompts, lower hallucination rates, and predictable performance at scale.
Related Posts
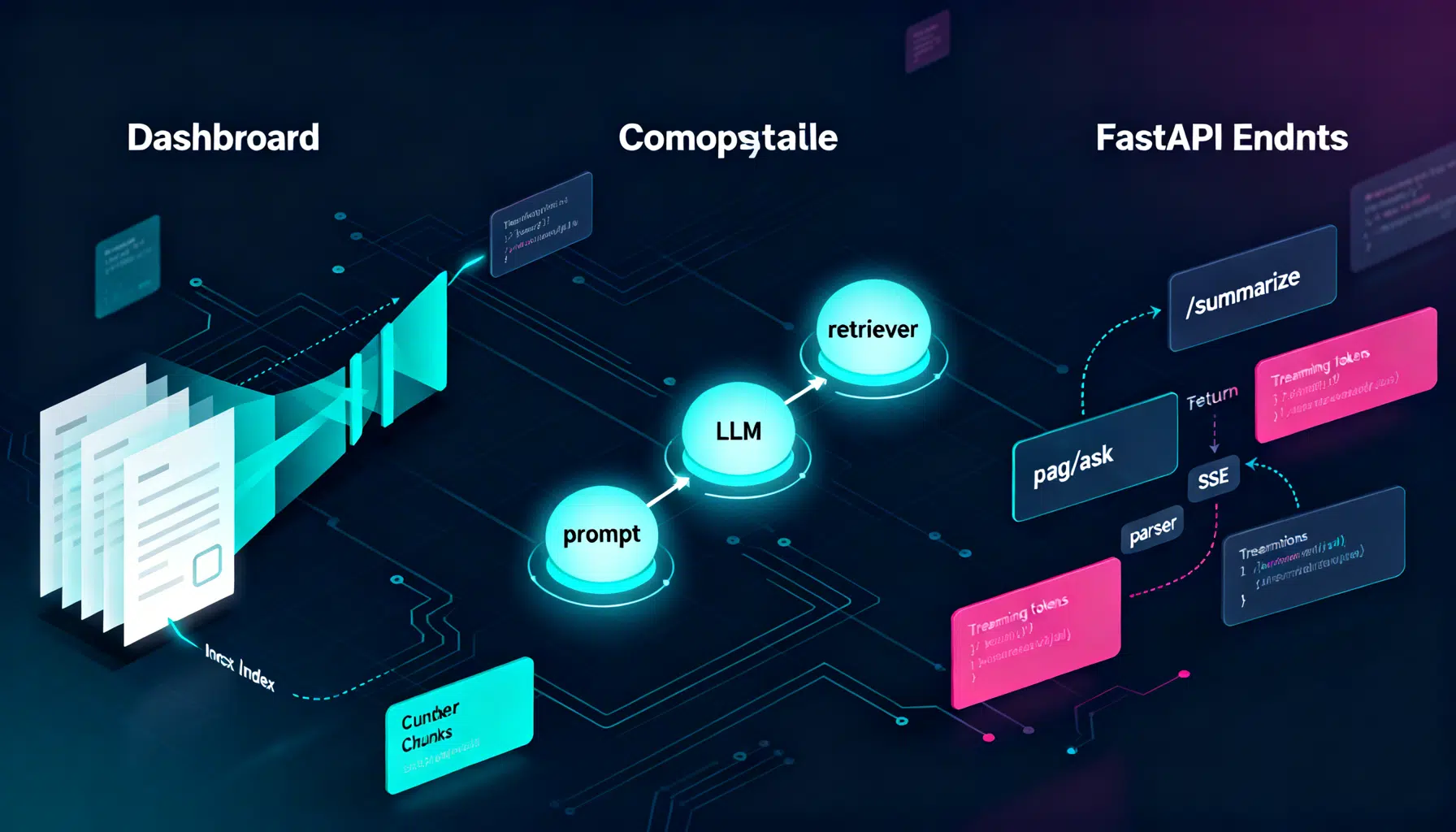
LangChain API Tutorial: From Hello World to Production RAG with FastAPI and LangServe
Build a production-ready LangChain API: LCEL chains, LangServe, FastAPI streaming, RAG, structured outputs, testing, and deployment tips.
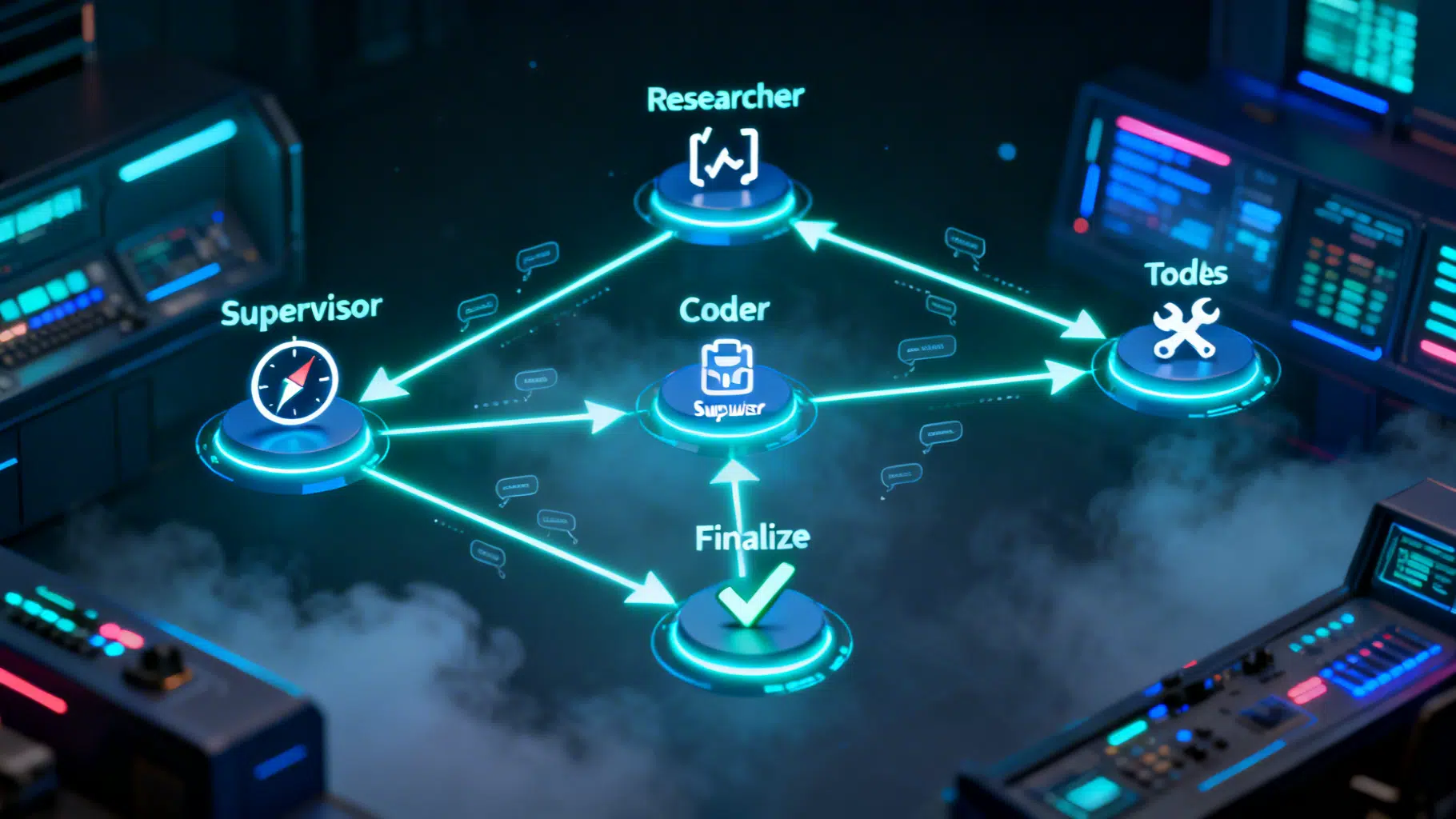
LangGraph Multi‑Agent Workflow Tutorial: From Supervisor Routing to Tool Execution
Build a production-ready LangGraph multi-agent workflow with a supervisor, tools, checkpointing, and streaming—step-by-step with tested Python code.

DeepSeek API Integration Tutorial: From First Call to Production
Step-by-step DeepSeek API integration: base URL, models, cURL/Python/Node code, streaming, thinking mode, tool calls, errors, and production tips.