Mixture-of-Experts (MoE) Architecture: A Practical, Engineer’s Guide
A clear, practical guide to Mixture-of-Experts (MoE) architecture: routing, experts, training stability, distributed systems, and when to use it.
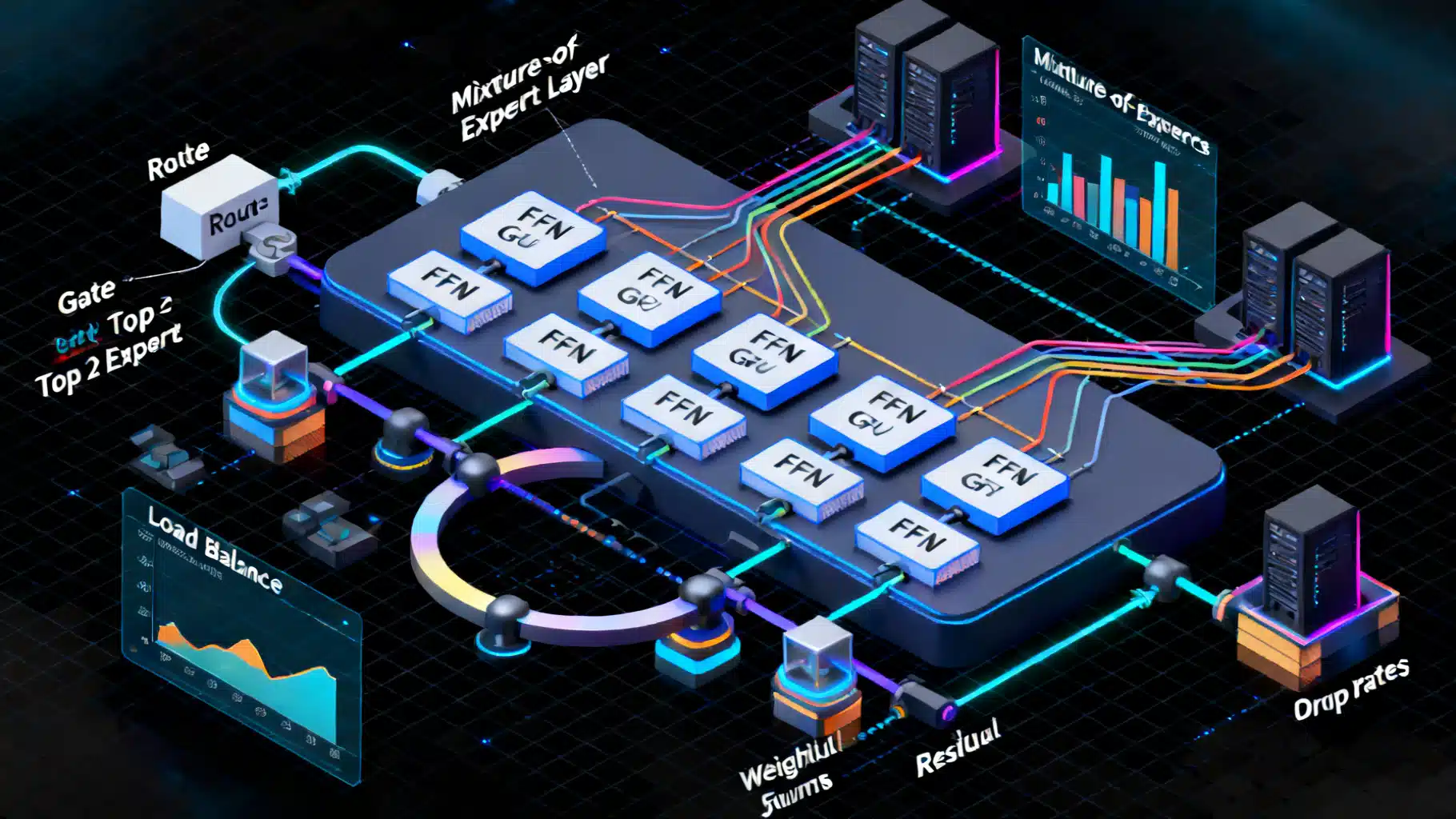
Image used for representation purposes only.
Overview
Mixture-of-Experts (MoE) is a neural network architecture that increases model capacity without proportionally increasing compute per token. Instead of activating all parameters for every input, MoE uses a router (or gate) to select a small subset of specialized sub-networks—experts—for each token. This sparse activation delivers high parameter counts at near-constant inference/training cost per token, making MoE a popular choice for large language and vision-language models.
Why MoE
- Scale capacity: Billions to trillions of parameters with manageable FLOPs/token.
- Specialization: Different experts learn domain- or pattern-specific behaviors.
- Flexibility: Can retrofit into Transformer blocks to replace dense feed-forward networks (FFNs).
- Throughput: With expert parallelism and efficient collectives, MoE can improve wall-clock performance at scale.
Trade-offs include routing instability, communication overhead, and engineering complexity for distributed training/serving.
The MoE Layer Anatomy
An MoE layer typically replaces the Transformer FFN with:
- Router (Gating Network): Maps token representations to a distribution over experts.
- Dispatch: Sends each token to top-k experts (often k=1 or k=2) with associated gate weights.
- Experts: Independent FFNs (or other sub-networks) that process assigned tokens.
- Combine: Aggregates expert outputs, weighted by gate probabilities, back to token order.
Formally, for token h, the router computes p = softmax(W_r h), then selects top-k indices S ⊂ {1..E}. The output is ∑_{e∈S} p_e · Expert_e(h), optionally with capacity limits and padding.
Routing Strategies
- Top-1 (Switch-style): Each token is sent to a single expert. Simplest and most efficient, often strongest throughput; may reduce representational mixing.
- Top-2: Each token visits two experts; improves quality and robustness at modest extra cost.
- Noisy Top-k: Adds noise before softmax to spread load and avoid expert collapse early in training.
- Hash/Deterministic Routing: Uses hash functions for token→expert mapping; eliminates router parameters but can reduce adaptivity.
- Expert-Choice vs Token-Choice: Token-choice (standard) sends tokens to their chosen experts. Expert-choice lets experts pull tokens they prefer (can improve balance at scale).
Capacity and Token Batching
Experts have a capacity: the max tokens they process per step. If a selected expert exceeds capacity, overflow tokens may be dropped or reassigned. A capacity factor (>1.0) scales expected tokens per expert to reduce drops. Typical settings:
- capacity_factor: 1.0–2.0 (higher reduces drops but increases padding/communication)
- k (top-k): 1 or 2
Auxiliary Losses for Balance
Without regularization, routers often overuse a few experts (“expert collapse”). Common remedies:
- Load-balancing loss: Encourages uniform token counts and probability mass across experts (e.g., product of fraction-of-tokens and fraction-of-probability).
- Router z-loss / entropy regularization: Penalizes extreme logits to stabilize routing.
- Expert dropout: Stochastically disables selected experts during training for robustness and balance.
These terms are added to the main loss with small coefficients (e.g., 1e-2 to 1e-4), tuned per scale.
Where MoE Fits in a Transformer
MoE is most commonly inserted in place of the FFN sublayer:
- Self-Attention (dense)
- MoE-FFN (sparse)
- Residual + LayerNorm
Not all layers are MoE. Many designs interleave MoE and dense FFNs (e.g., every other block) to maintain stable training and avoid router over-dependence.
Minimal PyTorch-Style Skeleton
import torch
import torch.nn as nn
import torch.nn.functional as F
class TopKRouter(nn.Module):
def __init__(self, model_dim, num_experts, k=1, noisy=False):
super().__init__()
self.w = nn.Linear(model_dim, num_experts, bias=False)
self.k = k
self.noisy = noisy
def forward(self, x): # x: [T, B, D]
logits = self.w(x) # [T, B, E]
if self.noisy and self.training:
logits = logits + torch.randn_like(logits) * 1e-2
probs = F.softmax(logits, dim=-1)
topk = probs.topk(self.k, dim=-1) # values, indices
return topk.values, topk.indices, probs
class ExpertFFN(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.w2(F.gelu(self.w1(x)))
class MoE(nn.Module):
def __init__(self, d_model, d_ff, num_experts, k=1, capacity_factor=1.25):
super().__init__()
self.router = TopKRouter(d_model, num_experts, k)
self.experts = nn.ModuleList([ExpertFFN(d_model, d_ff) for _ in range(num_experts)])
self.capacity_factor = capacity_factor
def forward(self, x):
T, B, D = x.shape
gate_vals, gate_idx, probs = self.router(x)
E = len(self.experts)
# Build dispatch buffers
capacity = int(self.capacity_factor * (T*B*self.router.k)/E) + 1
expert_inputs = [torch.zeros(capacity, B, D, device=x.device) for _ in range(E)]
expert_counts = [0]*E
combine_info = [] # to scatter back
for t in range(T):
for b in range(B):
for r in range(self.router.k):
e = int(gate_idx[t,b,r])
if expert_counts[e] < capacity:
pos = expert_counts[e]
expert_inputs[e][pos,b] = x[t,b]
combine_info.append((t,b,e,pos,float(gate_vals[t,b,r])))
expert_counts[e] += 1
# Expert forward
expert_outputs = [self.experts[e](expert_inputs[e]) for e in range(E)]
# Combine
y = torch.zeros_like(x)
for (t,b,e,pos,w) in combine_info:
y[t,b] += w * expert_outputs[e][pos,b]
return y
Notes:
- Real implementations vectorize dispatch/combine and rely on optimized all-to-all collectives for multi-GPU expert parallelism.
- You will also add load-balancing and router regularization losses.
Distributed Training and Parallelism
MoE adds a new axis of parallelism: expert parallelism.
- Data parallelism (DP): Replicate model, shard data.
- Tensor/model parallelism (TP): Split large weight matrices across devices.
- Pipeline parallelism (PP): Partition layers across stages.
- Expert parallelism (EP): Shard experts across devices; route tokens across nodes using all-to-all.
Key engineering considerations:
- All-to-all collectives: Dominant cost at scale; favor large batch sizes and token packing to amortize overhead.
- Overlap compute and communication: Start expert compute as soon as partial tokens arrive.
- Capacity tuning: Balance drop rate vs padding to minimize wasted compute.
- Fault tolerance: Routing is data-dependent; ensure deterministic seeding/checkpointing across nodes.
Popular toolchains include specialized MoE kernels and dispatch libraries that integrate with training frameworks to optimize routing and collectives.
Inference and Serving
- Static vs dynamic routing: Production often uses the same router but may quantize it and the experts separately.
- Batch shaping: Group tokens by expert to reduce all-to-all calls; microbatching helps.
- Caching: Router outputs can be reused across steps for long contexts when representations change slowly (approximate).
- Scale-out: EP across multiple inference nodes, often combined with tensor parallelism for attention layers.
Latency-sensitive setups sometimes prefer top-1 routing, aggressive capacity factors near 1.0, and pinned memory for dispatch buffers.
Quality, Stability, and Debugging
Common failure modes:
- Expert collapse: Few experts receive most tokens. Mitigate with higher load-balance loss, noisy routing, expert dropout, or increased k.
- Token drops: If capacity too low, quality degrades. Monitor drop rates; aim for <1–3% in steady state.
- Router divergence: Router logits saturate. Add z-loss/entropy reg, reduce router LR, or clip logits.
- Overfitting of experts: Specialists overshoot niche distributions. Use stronger regularization and mix dense FFN layers.
Diagnostics to track:
- Per-expert token counts and probability mass histograms.
- Drop rates and padding ratios.
- Router entropy and gradient norms.
- Quality vs compute curves when varying k and capacity.
Design Variants
- Multi-Task MoE: Experts specialize per task/domain, sometimes with task-aware priors or prompts.
- Hierarchical MoE: Two-level routers; coarse selection of expert groups followed by fine selection.
- Modular experts: Replace FFNs with convolutional or attention-based experts for multimodal workloads.
- Shared experts: Some experts shared across layers to reduce memory.
- Gated Dense+Sparse: Blend a small dense FFN with MoE output for stability.
Practical Configuration Cheatsheet
- Number of experts (E): Start with 8–64 for single node; 64–256+ for multi-node.
- Top-k: Use 1 for speed, 2 for quality; tune.
- Capacity factor: 1.0–1.25 for production latency; 1.25–2.0 for training quality.
- Router temperature/noise: Small Gaussian noise early in training to spread load.
- Aux loss weights: 1e-3 (load-balance) and 1e-5–1e-4 (z-loss) as starting points.
- Expert size: Keep per-expert FFN hidden comparable to dense baseline’s FFN; total capacity scales with E.
- Optimizer: AdamW or Adafactor; consider lower LR for router parameters or use separate schedule.
When (Not) to Use MoE
Use MoE if:
- You need massive capacity for multi-domain data and can afford distributed training complexity.
- You target high throughput at near-constant FLOPs/token.
Prefer dense models if:
- Data scale is small or homogeneous; specialization won’t help.
- Infrastructure cannot support all-to-all or complex parallelism.
- Low-latency single-GPU serving is required and EP is infeasible.
Evaluation and Ablations
- Compare to dense baselines at similar compute budgets (FLOPs/token), not just parameter count.
- Ablate k, capacity, aux losses, and MoE frequency (every layer vs interleaved).
- Report utilization metrics alongside accuracy/quality to ensure fair, stable routing.
Future Directions
- Learned modularity with continual/expert growth.
- Better router objectives (e.g., information-theoretic or task-aware) to minimize collapse.
- Communication-efficient routing (compressed or localized all-to-alls, expert caching).
- MoE for multimodal transformers with expert types matched to modalities and tasks.
Key Takeaways
- MoE scales capacity via sparse activation, enabling large models at manageable per-token cost.
- Success depends on stable routing, balanced utilization, and efficient distributed systems.
- With careful tuning and engineering, MoE can deliver state-of-the-art quality-to-compute trade-offs for large-scale modeling.