Designing REST API Batch Operations: Patterns, Semantics, and Examples
Designing robust REST API batch operations: models, atomicity, idempotency, error handling, async jobs, limits, and examples.
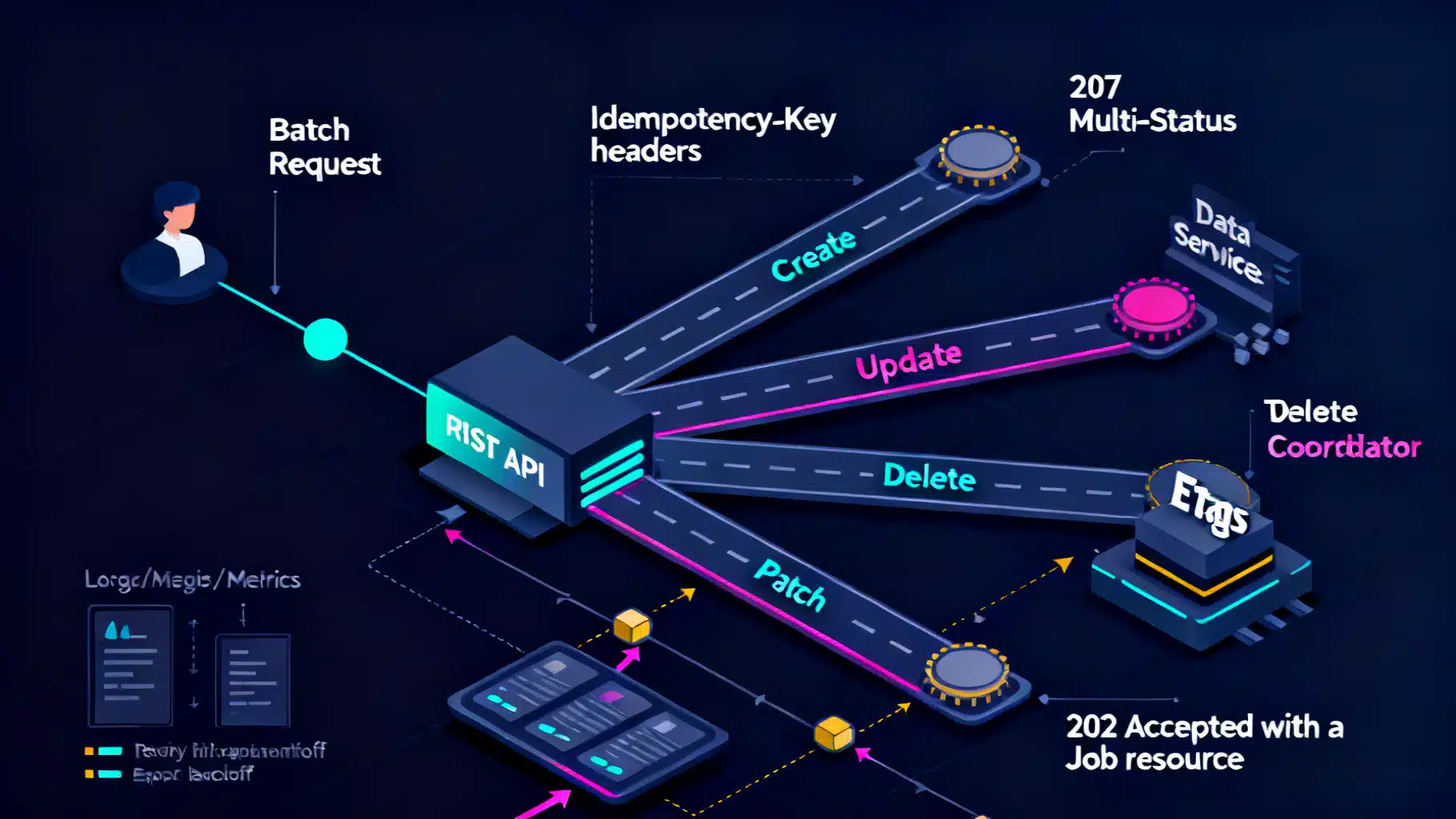
Image used for representation purposes only.
Overview
Batch operations let REST APIs perform many similar actions in a single request—reducing round‑trips, improving throughput, and making large-scale changes safer and faster. Done poorly, they create opaque failures, lock contention, and painful debugging. This guide distills proven patterns for designing robust, predictable, and evolvable batch endpoints.
When to use batching (and when not to)
Use batching when:
- You need to create/update/delete many resources at once (imports, nightly syncs, bulk edits).
- Latency dominates throughput (mobile, cross‑region, or strict SLA contexts).
- Server-side logic benefits from set‑based processing (deduplication, validation, single transaction).
Avoid or limit batching when:
- Each operation requires user interaction or distinct authorization prompts.
- You need strong isolation between items (fail-fast behavior per item is preferred).
- Streaming/long‑lived ingestion pipelines or event-driven systems are a better fit.
Resource shapes for batch endpoints
Common, REST‑friendly shapes:
- Subresource on a collection: POST /v1/users:batch or POST /v1/users/_batch
- Action subresource for mixed ops: POST /v1/batch-operations
- Explicit job resource for async work: POST /v1/batch-jobs → 202 Accepted + Location: /v1/batch-jobs/{id}
Favor a small number of predictable batch endpoints over sprinkling batch flags across many single‑item endpoints.
Request envelope design
Design a consistent, typed envelope that can carry many operations.
Example: mixed create/update/delete for a single resource type
POST /v1/users:batch HTTP/1.1
Content-Type: application/json
Idempotency-Key: 84e6b7a3-5c5d-4103-9d8c-8c2b5aa3a7b1
{
"atomic": false,
"ordered": true,
"dryRun": false,
"items": [
{
"op": "create",
"clientId": "tmp-1",
"body": {"email": "a@example.com", "name": "Ada"}
},
{
"op": "update",
"id": "usr_123",
"ifMatch": "W/\"v5\"",
"body": {"name": "Grace"}
},
{
"op": "delete",
"id": "usr_456"
}
]
}
Notes:
- atomic: all‑or‑nothing semantics (true) vs best‑effort (false).
- ordered: if true, stop on first failure; if false, process independently.
- dryRun: validate without applying changes; include full validation feedback.
- clientId: a temporary handle so later items can reference earlier creations (e.g., for relationships) without server IDs yet.
- ifMatch: per‑item optimistic concurrency (ETag or version).
Response modeling and status codes
Return an envelope with per‑item outcomes and a concise summary. Keep HTTP status meaningful for the whole request:
- 200 OK or 201 Created: Synchronous success (even with partial success, prefer 200 or 207—see below).
- 207 Multi-Status: Mixed outcomes in a best‑effort batch.
- 202 Accepted: Async processing; respond with a job resource.
- 4xx/5xx: The envelope is invalid or the server could not even begin meaningful processing.
Example best‑effort response with partial failures using RFC 7807 (application/problem+json) semantics per item:
HTTP/1.1 207 Multi-Status
Content-Type: application/json
X-Request-Id: 1c1a7d95b66d4e31
{
"summary": {
"total": 3,
"succeeded": 2,
"failed": 1
},
"items": [
{
"index": 0,
"op": "create",
"status": 201,
"id": "usr_789",
"clientId": "tmp-1",
"etag": "W/\"v1\"",
"location": "/v1/users/usr_789"
},
{
"index": 1,
"op": "update",
"status": 412,
"error": {
"type": "https://example.com/problems/precondition-failed",
"title": "Precondition Failed",
"detail": "If-Match did not match current ETag.",
"instance": "urn:request:1c1a7d95b66d4e31:item:1"
},
"id": "usr_123"
},
{
"index": 2,
"op": "delete",
"status": 204,
"id": "usr_456"
}
]
}
Guidelines:
- Include index to correlate response items to request order.
- Always return per‑item status. Prefer numeric codes and optional problem+json objects.
- Include ETag/versions and Location where applicable.
- For atomic=true, either all items succeed or the response is a single error describing the rollback decision.
Atomicity options
Expose explicit control; default to best‑effort for resilience:
- atomic=true (transactional): Either execute all operations in one transaction or simulate via compensating actions if cross‑shard. Return 200/201 on success; 409/422 with a top‑level problem object on any failure.
- atomic=false (best‑effort): Each item applied independently; report granular successes/failures with 207 Multi-Status and a summary.
Document limits: maximum items per batch, maximum bytes, and whether cross‑resource transactional semantics are supported.
Idempotency and de‑duplication
Batches amplify the impact of retries. Provide strong guarantees:
- Require Idempotency-Key for unsafe methods (POST/DELETE) and honor it across a configurable window.
- Allow per‑item client‑supplied idempotency tokens (e.g., requestId). Store outcome fingerprints to return the same result on replay.
- For creates, accept client‑generated IDs or upsert semantics where appropriate (PUT with known ID or POST with idempotency key).
- Ensure idempotency covers both success and error outcomes.
Concurrency control per item
Combine optimistic concurrency and conditional requests:
- Accept ifMatch (ETag/version) and ifUnmodifiedSince per item.
- For collections that support merge‑patch or JSON Patch, allow op‑specific concurrency control.
- Respond 412 Precondition Failed per item if the precondition does not hold.
Validation, ordering, and dependencies
- Validate entire payload first for shape and size; return 400 if the envelope is invalid.
- If ordered=true, stop on first failure and report the index where it occurred.
- Support clientId references: later items can refer to previously created items via a reference field, resolved within the batch.
- Offer dryRun for schema/authorization/uniqueness checks without side effects.
Synchronous vs asynchronous processing
For large or slow batches, prefer asynchronous jobs.
Synchronous threshold policy:
- If items <= N and estimated work < T ms, process synchronously.
- Otherwise return 202 Accepted with a job resource.
Example async flow:
POST /v1/users:batch HTTP/1.1
Content-Type: application/json
{ "atomic": false, "items": [/* 50k updates */] }
HTTP/1.1 202 Accepted
Location: /v1/batch-jobs/job_9f34
Retry-After: 10
Content-Type: application/json
{
"id": "job_9f34",
"state": "queued",
"submittedAt": "2026-05-03T17:29:00Z",
"progress": {"total": 50000, "processed": 0, "succeeded": 0, "failed": 0}
}
Job resource representation:
GET /v1/batch-jobs/job_9f34 HTTP/1.1
{
"id": "job_9f34",
"state": "running",
"progress": {"total": 50000, "processed": 15000, "succeeded": 14790, "failed": 210},
"links": {
"results": "/v1/batch-jobs/job_9f34/results",
"errors": "/v1/batch-jobs/job_9f34/errors",
"cancel": "/v1/batch-jobs/job_9f34/cancel"
}
}
Support cancellation, partial result streaming (e.g., NDJSON), backoff hints via Retry-After, and webhooks/callback URLs when appropriate.
Error handling and problem details
Standardize errors to make client tooling predictable:
- Use application/problem+json for top-level and per‑item errors.
- Include machine‑readable type URIs, and stable error codes.
- Provide human‑readable title/detail, plus contextual fields (resource, constraint, field, expected/current value).
- Return a top‑level X-Request-Id and mirror it in job resources and logs for tracing.
Limits, quotas, and abuse protection
- Enforce server‑side caps: maxItems, maxPayloadBytes, maxOpsPerSecond per token.
- Respond 413 Payload Too Large for oversize bodies and 429 Too Many Requests for quota breaches; include Retry-After and rate‑limit headers.
- Encourage compression (Content-Encoding: gzip or zstd) and chunked upload where supported.
- Validate early and fail fast on obviously malicious payloads.
Performance considerations
- Prefer set‑based queries and bulk DML at the datastore layer.
- Be explicit about ordering costs; unordered batches allow more parallelism.
- Consider 207 Multi-Status for best‑effort to reflect mixed outcomes cleanly.
- For very large results, expose paged results endpoints under the job resource; optionally support NDJSON streaming.
- Cache invariants: cache read‑only subresources (e.g., reference data) to reduce per‑item validation cost.
Versioning and evolvability
- Version batch endpoints like other resources (e.g., /v1/…).
- Additive changes only: new optional fields, new op types, and new error types must be non‑breaking.
- Use feature discovery: expose capabilities (max limits, supported ops) via OPTIONS or a capabilities endpoint.
Security and authorization
- Evaluate authorization per item—return 403 for individual denials without failing the whole batch (unless atomic=true).
- Support scoped tokens; document which scopes are needed per op.
- Redact sensitive fields in logs and error payloads.
- Consider per‑item tenancy checks to prevent cross‑tenant references inside a batch.
Observability and diagnostics
- Correlate: X-Request-Id, per‑item instance URNs, and job IDs.
- Emit structured logs with batchId, itemIndex, op, result, latency.
- Metrics: total items, success rate, P50/P95/P99 per‑item latency, queue depth for jobs, retries, dedup hits.
- Tracing: include span links for per‑item operations when sampling.
Data models for updates
Choose update semantics deliberately:
- PUT replaces the full representation (idempotent); use sparingly in batches due to payload size.
- PATCH for partial updates; consider application/merge-patch+json for simplicity or application/json-patch+json for precise operations.
- Document how null vs omission behaves (clear vs ignore).
Example JSON Merge Patch per item:
{
"op": "patch",
"id": "usr_123",
"contentType": "application/merge-patch+json",
"body": {"name": "Alan", "title": null}
}
Referencing within a batch
Enable intra‑batch relationships using clientId mapping:
{
"op": "create",
"clientId": "team-1",
"body": {"name": "Platform"}
}
Later item:
{
"op": "create",
"body": {"email": "pm@example.com", "team": {"clientId": "team-1"}}
}
Server resolves clientId → persisted ID, validates tenancy, and returns the mapping in the response.
SDK ergonomics
- Provide typed results with a union of success/error per item.
- Include helpers for chunking large inputs to server limits.
- Automatic retries on safe conditions using Idempotency-Key and Retry-After hints.
- Rich error types that preserve item index and problem details.
End-to-end example checklist
- Endpoint: POST /v1/resources:batch
- Envelope: atomic, ordered, dryRun, items[] with op, id/clientId, body, ifMatch
- Limits: maxItems, maxPayloadBytes, rate limits, compression
- Concurrency: ETag/If-Match per item
- Idempotency: Idempotency-Key header and per‑item tokens
- Errors: per‑item status + problem+json; 207 for mixed outcomes
- Async: 202 + job resource with progress, results, cancel
- Observability: X-Request-Id, indices, instance URNs, metrics
- Security: per‑item auth, tenancy checks, scope validation
- Versioning: additive changes and capability discovery
Conclusion
Well‑designed batch operations turn high‑latency, error‑prone multi‑call workflows into predictable, efficient API interactions. By making atomicity explicit, errors precise, idempotency strong, and async pathways first‑class, you’ll deliver bulk functionality that scales operationally and is delightful to integrate.
Related Posts

REST API Error Handling Best Practices: A Practical, Modern Guide
A practical guide to REST API error handling: status codes, structured responses (RFC 7807), retries, rate limits, idempotency, security, and observability.

REST API Soft Delete Patterns: Models, Endpoints, and Production Pitfalls
A practical guide to soft delete in REST APIs: models, endpoints, filtering, restore, cascades, auditing, and pitfalls—plus SQL and HTTP examples.
Standardizing REST API Responses: A Practical Guide with Examples
A practical guide to standardizing REST API responses—status codes, envelopes, errors, pagination, headers, and examples to build resilient, consistent APIs.