Designing a Robust AI Customer Support Chatbot Architecture
A practical blueprint for building scalable, safe AI support chatbots—from NLU and RAG to orchestration, guardrails, and observability.
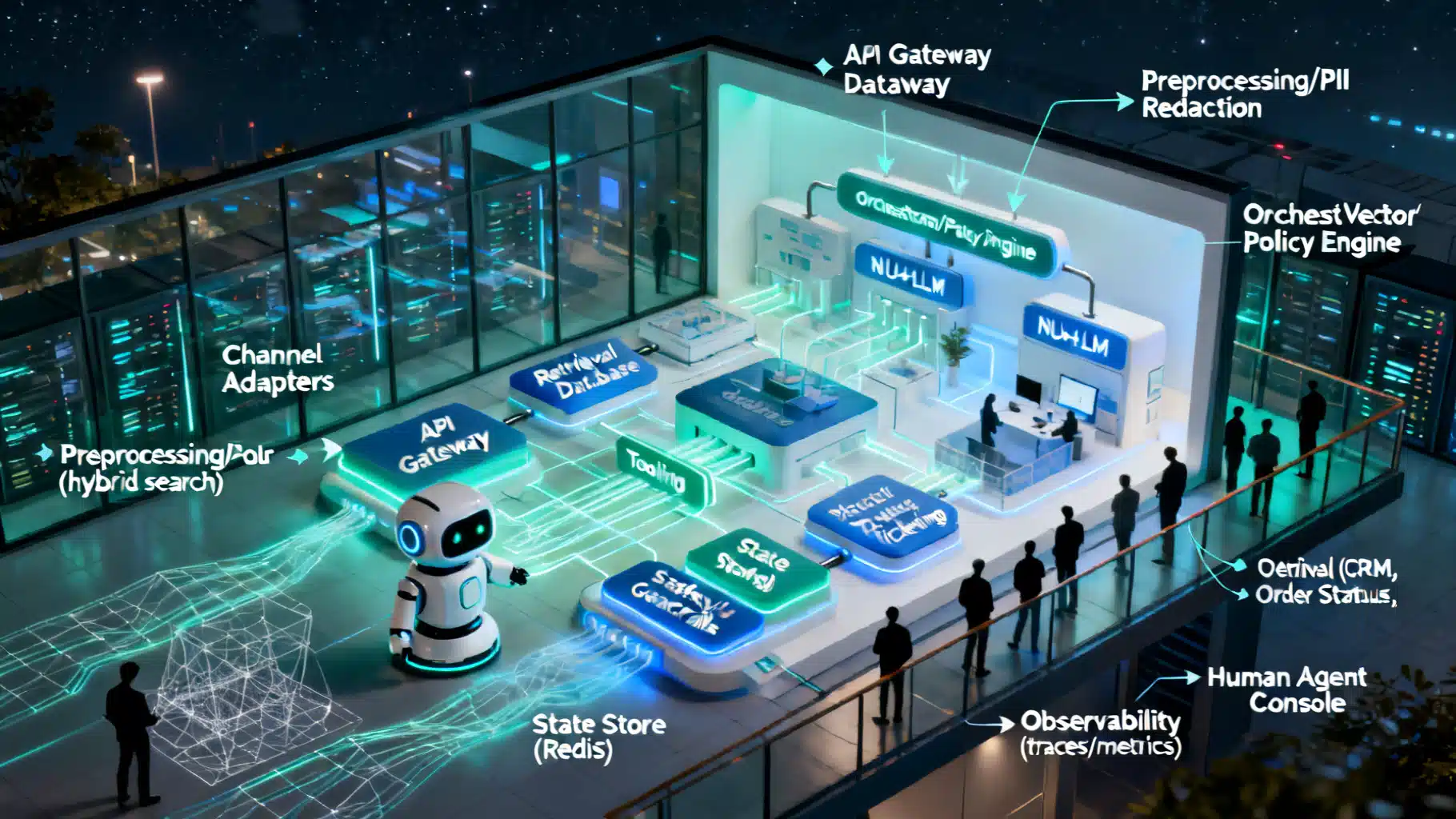
Image used for representation purposes only.
Overview
AI customer support chatbots have matured from scripted decision trees into full-stack systems that combine retrieval, reasoning, tools, and guardrails. A robust architecture must deliver accurate answers, safe behaviors, low latency, and clear paths to a human agent—while remaining observable, updatable, and cost‑efficient. This article lays out a pragmatic blueprint you can adapt to your stack.
Reference Architecture at a Glance
A production-ready chatbot typically spans these layers:
- Channels: Web widget, mobile SDK, email, SMS, social, voice/IVR.
- Ingress and routing: API gateway, auth, rate limiting, traffic shaping, canaries.
- Preprocessing: PII redaction, language detection, normalization, spam/abuse filtering.
- Orchestrator: Conversation controller that decides retrieval vs. tools vs. generation, applies policies, and manages retries/timeouts.
- NLU/LLM: Intent detection, entity extraction, classification, and generative reasoning.
- Retrieval (RAG): Document store, vector DB, hybrid search, chunking, re-ranking, citation management.
- Tooling: Function calling into CRM, ticketing, order status, billing, knowledge sources.
- State and memory: Short-term turn memory, long-term user profile, session storage.
- Safety and compliance: Input/output filters, jailbreak defenses, data loss prevention (DLP), consent and audit.
- Response shaping: Tone, localization, formatters, channel-specific renderers.
- Handoff: Trigger logic, context packaging, and routing to human agents.
- Observability: Tracing, metrics, logs, evaluations, feedback loops.
- Lifecycle: Prompt/model/version management, offline/online evals, rollback.
Request Lifecycle (End-to-End)
- Message enters via a channel adapter (e.g., web widget) and hits the API gateway.
- Identity is resolved (JWT/SSO/session). Rate limits and basic bot/abuse checks run.
- Preprocessors redact PII where required and normalize text (spelling, emojis, language).
- Orchestrator builds a request context: user profile, session state, channel, locale, business hours, entitlements.
- Policy engine decides: retrieval-only, tool-first (e.g., order lookup), or free-form generation with guardrails.
- If RAG: query rewriting → vector+keyword search → re-ranking → evidence pack with citations.
- If tools: schema-based function calls to CRM/ERP with timeouts, retries, idempotency keys.
- LLM composes the response using instructions, tools, and retrieved evidence; safety filters validate outputs.
- Response renderer formats text, quick replies, forms, or voice SSML; attaches citations where appropriate.
- State is updated; analytics/traces are emitted; triggers for escalation/handoff fire if necessary.
Channel Adapters and Gateway
- Support multiple ingress paths: REST, WebSocket for streaming, and webhook-based social channels.
- API gateway features:
- Authentication/authorization (user, tenant, bot-to-bot).
- Rate limiting and token-bucket quotas per tenant.
- Canary routing (percentage-based), circuit breakers, and global timeouts.
- Request/response size limits and content-type validation.
Identity, Session, and Context
- Single Sign-On (OIDC/SAML) and JWTs to link users to CRM records.
- Session state in a low-latency store (e.g., Redis) with TTL and sliding expiration.
- Context assembly: locale, preferences, entitlement flags, recent orders, last ticket, SLA tier.
- Privacy: encrypt sensitive attributes at rest; never persist raw secrets in session.
Preprocessing and PII Controls
- Language detection to route to the correct prompt and knowledge base.
- Normalization: punctuation, emoji mapping, contraction expansion, profanity masking.
- PII/DLP: redact or mask card numbers, SSNs, email addresses; store only salted hashes where correlation is required.
Orchestrator and Policy Engine
The orchestrator is the decision brain that sequences retrieval, tool calls, and generation.
- Policies:
- Safe defaults (“answer only from retrieved content for regulated domains”).
- Capability gating (e.g., refunds require 2FA + supervisor policy).
- Escalation triggers by topic, confidence, or sentiment.
- Execution model: structured tool calling with explicit schemas; fan-out for parallel tool queries; hedged requests for tail latency.
- Resilience: deadline propagation, retries with jitter, and fallbacks (smaller models, cached answers, FAQ flows).
NLU and Intent Handling
Even with powerful LLMs, a thin NLU layer is valuable:
- Lightweight classifiers for routing (billing vs. tech support vs. sales).
- Entity extraction for IDs (order, account), product names, and dates.
- Deterministic intents for critical flows (password reset, outage notices) to reduce ambiguity and cost.
- Confidence signals feed the policy engine to choose deterministic flows vs. generative reasoning.
Retrieval-Augmented Generation (RAG)
Accurate answers hinge on a disciplined RAG design:
- Ingestion pipeline: HTML/PDF parsing, layout-aware chunking, de-duplication, PII scrubbing.
- Embeddings: choose multilingual vectors if supporting multiple locales; store metadata (locale, product, version, effective date).
- Hybrid search: vector similarity + BM25 keyword + filters (locale, product line, region).
- Re-ranking: learned or cross-encoder re-ranker for top-k context quality.
- Evidence pack: include chunk text, titles, anchors, and URLs for transparency.
- Freshness: incremental updates with change data capture; store document version and validity windows.
- Caching: query and answer caches keyed by normalized question + tenant.
Tooling and Function Calling
- Define tools with JSON schemas: input validation, parameter hints, and example payloads.
- Common tools: CRM lookup, order tracking, ticket creation, refund estimation, outage status, appointment booking.
- Operational safeguards:
- Timeouts and circuit breakers per tool.
- Rate limits and quotas to protect downstream systems.
- Idempotency keys for mutations (ticket create, refund approve).
- Shadow/test modes for new tools with synthetic traffic.
Prompt and Response Management
- Prompt templates: system + developer + user + tool results; keep versions in a registry.
- Style guides: brand voice, empathy statements, short vs. long form, channel-specific tokens.
- Structured outputs: require JSON when calling tools or logging; validate with JSON schema.
- Localization: variable placeholders, gender/number agreements, date/number formatting by locale.
Dialogue State and Memory
- Short-term memory: last N turns, tool results, pending confirmations; stored per session.
- Long-term memory: user profile and preferences with explicit consent and retention windows.
- Guard against “runaway memory” by pruning and summarizing; store only what you must for the task.
Safety, Guardrails, and Compliance
- Input filters: prompt-injection and jailbreak pattern checks; content moderation; malware/URL checks.
- Output filters: PII leakage detection, restricted topics, compliance phrases.
- High-risk actions: require explicit confirm steps, 2FA, or human approval.
- Auditability: store signed inference traces (hashes) and decision logs for disputed cases.
- Regulatory: map data flows for GDPR/CCPA; implement data subject request endpoints; configure regional data residency.
Human Handoff and Agent Assist
- Triggers: low confidence, high sentiment negativity, VIP flag, repeated failures, regulated intents.
- Package the transcript, retrieved evidence, and tool outputs into the handoff payload.
- Agent console add-ons: suggested replies, live knowledge search, macro expansion, and after-call summaries.
Observability and Evaluation
- Tracing: end-to-end spans across gateway, orchestrator, retrieval, tools, and LLM; attach prompt, version, and latency.
- Metrics: containment rate, first contact resolution (FCR), CSAT, average handle time (AHT), answer accuracy, hallucination rate, escalation rate, cost per conversation.
- Feedback: thumbs up/down with rationale; post-chat surveys; analyst labeling UI for gold sets.
- Evaluation: offline regression on curated datasets; online A/B for prompt/model changes; QoS SLOs per tenant.
Performance and Cost Controls
- Latency:
- Stream token output to show progress.
- Use smaller, faster models for classification and query rewriting.
- Parallelize retrieval and tool calls; warm connection pools.
- Apply top-k pruning and re-ranking to minimize context size.
- Cost:
- Caching at multiple layers (embeddings, retrieval, final answer where safe).
- Adaptive model routing by difficulty/confidence.
- Distilled domain models for frequent intents.
- Chunk/window optimization to reduce prompt tokens.
Deployment Patterns
- Containers with horizontal autoscaling for the orchestrator and retrieval API.
- Serverless functions for bursty, stateless pre/post-processing.
- GPU pools for embedding/LLM inference where self-hosted; use model gateways for multi-model routing.
- Safe rollout: feature flags, prompt/model canaries, and automated rollback on KPI regression.
Data Lifecycle and Governance
- Ingestion governance: approvals and provenance tracking for new knowledge sources.
- Retention policies by data class (transcripts vs. PII vs. telemetry).
- Redaction at source, not just at query time.
- Periodic red-teaming and policy audits; track drift in intents and top failure modes.
Multimodal, Multilingual, and Accessibility
- Voice: ASR pre-processing and TTS post-processing with domain lexicons.
- Images: allow users to upload screenshots; route to vision models for device/app troubleshooting.
- Multilingual: locale routing, bilingual RAG indexes, and human review loops for low-resource languages.
- Accessibility: WCAG-compliant widgets; keyboard navigation; screen reader-friendly responses.
Minimal Blueprint (Example)
ingress:
gateway: auth+rate_limit+canary
channels: [web_widget, sms, email]
preprocess:
- language_detect
- pii_redact
orchestrator:
policies: [retrieval_first, refund_requires_2fa]
tools: [crm_lookup, order_status, ticket_create]
llm_router: [fast_small_for_classify, mid_for_reason, large_for_edge]
retrieval:
vector_db: hybrid_search+rerank
index: knowledge_base@v23 (locale=en-US)
state:
session_store: redis
user_profile: encrypted_sql
safety:
input: [inj_protect, moderation]
output: [pii_leak_scan, restricted_topics]
observability:
tracing: end_to_end
metrics: [latency_p50_p95, cost_per_chat, containment]
Example Turn Flow (Pseudocode)
onMessage(msg, user):
ctx = buildContext(msg, user)
guardrails.checkInput(ctx)
route = policies.decide(ctx)
if route == "retrieval_first":
q = rewriteQuery(ctx)
docs = hybridSearch(q)
evidence = rerank(docs).top(5)
if route.requiresTool:
toolResult = callTool(route.tool, ctx)
draft = LLM.generate(systemPrompt, ctx, evidence, toolResult)
guardrails.checkOutput(draft)
reply = render(draft, channel=ctx.channel)
persistState(ctx, reply)
emitTelemetry(ctx, reply)
if needsHandoff(ctx, draft): escalateToHuman(ctx, draft)
return reply
Build vs. Buy Considerations
- Managed vs. self-hosted LLMs: managed for speed and elasticity; self-hosted for data control/cost predictability.
- Vector DB: choose based on hybrid search support, filters, durability, and operational maturity.
- Tooling/connectors: evaluate vendor ecosystems for CRM, ticketing, and payment integrations.
- Observability: prefer OpenTelemetry-compatible stacks to avoid vendor lock-in.
KPI Framework
- Containment rate (no human required) and FCR.
- Accuracy/grounding score (sampled, human-rated or LLM-as-judge with spot checks).
- CSAT and NPS deltas pre/post bot deployment.
- Average handle time, time-to-first-token, and p95 latency.
- Safety incidents per 1k conversations and PII leakage findings.
- Cost per resolved conversation and ROI vs. baseline.
Production Readiness Checklist
- Clear SLAs (availability, latency, containment).
- Canary plan with automatic rollback on KPI regressions.
- Gold evaluation sets and change-management gates for prompts/models.
- Robust RAG with provenance, citations, and freshness controls.
- Tool contracts with timeouts, retries, and idempotency.
- Defense-in-depth guardrails and audit logging.
- Handoff paths tested under load with real agent consoles.
- Observability: traces, metrics, logs, and dashboards wired to alerts.
- Data governance: retention, DSR handling, and access controls.
Conclusion
Great customer support chatbots are engineered systems, not just models. By investing in orchestration, retrieval quality, tool reliability, guardrails, and observability, you can deliver fast, accurate, and safe assistance—while keeping costs predictable and teams confident to iterate. Start small with a retrieval-first flow and a handful of tools, instrument everything, and expand capability as your evaluations and KPIs justify it.
Related Posts

Integrating an AI Writing Assistant via API: Architecture, Code, and Best Practices
A practical guide to integrating an AI writing assistant via API—architecture, prompt design, code samples, safety, evaluation, and performance optimization.
Function Calling vs. Tool Use in LLMs: Architecture, Trade-offs, and Patterns
A practical guide to function calling vs. tool use in LLMs: architectures, trade-offs, design patterns, reliability, security, and evaluation.

Open-Source LLM Deployment Guide: From Laptop Prototype to Production
Practical, end-to-end guide to deploying open-source LLMs—from model choice and hardware sizing to serving, RAG, safety, and production ops.