API Saga Pattern: Building Reliable Distributed Transactions at Scale
Designing reliable distributed transactions with the Saga pattern: orchestration vs choreography, API design, idempotency, compensations, and production pitfalls.
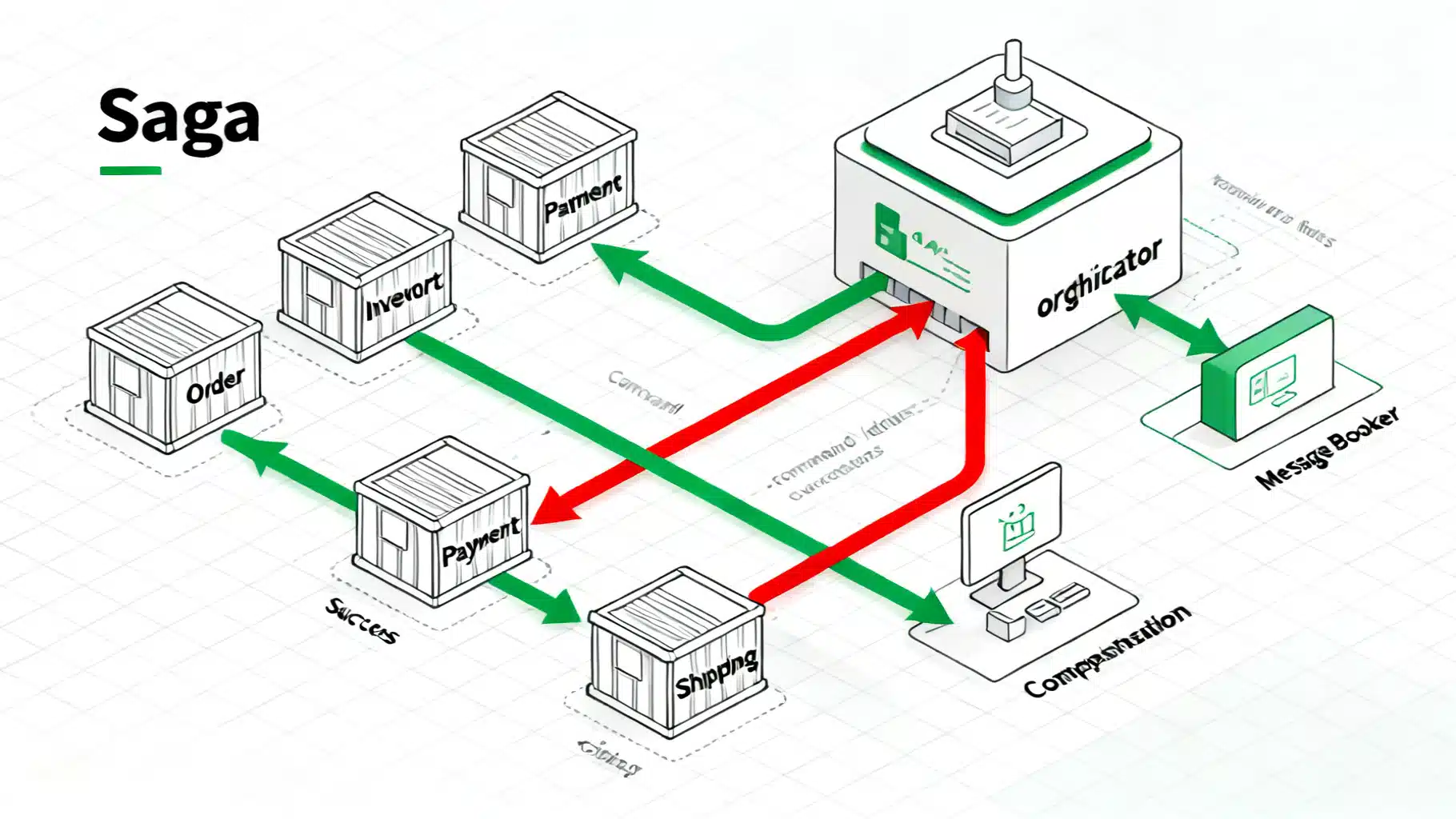
Image used for representation purposes only.
Why Distributed Transactions Are Hard
Modern systems spread business workflows across many independently deployed services. Each service owns its data and publishes APIs. That autonomy boosts scale and velocity, but it breaks the illusion of a single, atomic transaction. Two‑phase commit (2PC) across heterogeneous databases and clouds is fragile, slow, and operationally expensive. The Saga pattern offers a pragmatic alternative: split a long transaction into a sequence of local transactions and pair each step with a compensating action.
This article explains how to design APIs and infrastructure for Sagas, when to use orchestration vs. choreography, and the pitfalls that matter in production.
Saga Basics
A Saga is a long‑lived business process composed of ordered steps:
- Each step is a local transaction in one service (ACID within its own database).
- If a step fails, previously completed steps are undone via compensations.
- Consistency is eventual, not instantaneous; the saga either reaches a successful terminal state or a compensated terminal state.
Two common styles:
- Choreography (event-based): services react to events and emit new events. No central coordinator.
- Orchestration (command-based): a dedicated orchestrator invokes service APIs, tracks state, and triggers compensations.
When to Use Sagas (and When Not To)
Use Sagas when:
- A workflow spans 3+ services and 2PC is unavailable or impractical.
- Steps are decoupled enough to expose clear compensations (e.g., reserve → release inventory).
- Latency tolerance is seconds to minutes, not milliseconds.
Avoid or reconsider when:
- You require strict atomicity for a small number of participants that support XA/2PC and you can tolerate its trade‑offs.
- You cannot define safe compensations (e.g., irreversible external payments) and business policy cannot accept eventual consistency.
Orchestration vs. Choreography
- Orchestration
- Pros: centralized control and visibility, explicit timeouts and retries, simpler reasoning about order.
- Cons: potential bottleneck, single point to scale and secure, orchestrator becomes a mini “workflow engine.”
- Choreography
- Pros: high decoupling, services evolve independently, simple to start.
- Cons: implicit control flow, risk of event storms, hard to visualize and test end‑to‑end.
Rule of thumb: start with choreography for short, linear flows with 3–4 steps. Prefer orchestration for complex branching, compensations, and SLAs.
Designing APIs for Sagas
Your APIs should embrace eventual consistency and idempotency.
Key design elements:
- Idempotency keys: accept a client‑supplied key (e.g., Idempotency-Key header) for POST/command endpoints to deduplicate retries.
- Correlation IDs: include sagaId and correlationId in all requests and events for traceability.
- Command vs. event separation: synchronous commands over HTTP/gRPC; asynchronous events over a broker.
- Explicit compensation endpoints: expose actions to undo previous side effects, e.g., POST /reservations/{id}/release.
- Timeouts as first‑class: allow the caller to specify or discover timeouts; document default retry policies.
- Versioned contracts: evolve schemas with backward compatibility.
Example REST commands and compensations:
POST /orders # create (returns orderId, sagaId)
POST /inventory/reservations # reserve items (compensate: release)
POST /payments/authorizations # authorize (compensate: void)
POST /shipments/labels # allocate label (compensate: cancel)
Messaging and Delivery Semantics
Sagas live in the real world of partitions and retries. Design for at‑least‑once delivery.
- Outbox pattern: write business changes and pending events atomically to the service’s DB; a background relay publishes events to the broker, ensuring no lost events.
- Deduplication: consumers keep a processed‑message log keyed by messageId to ignore duplicates.
- Dead‑letter queues (DLQs): route poison messages for later inspection; alert on DLQ growth.
- Ordering: keep ordering within a sagaId partition key where required; avoid global ordering assumptions.
- Backoff and jitter: exponential backoff with jitter prevents thundering herds.
Saga State and Persistence
Even in choreography, you need a durable record.
- Orchestrator state store: persist saga instances, step states (Pending, Completed, Compensated, Failed), retries, and timeouts.
- Choreography audit log: materialize saga state by consuming events into a read model for observability.
- Id generation: use UUIDs or ULIDs per saga and per step; include them in all messages.
End‑to‑End Example: Order → Pay → Ship
Let’s implement the same business flow both ways.
Orchestrated Flow
- Client calls Orchestrator: POST /sagas/orders
- Orchestrator sends commands:
- Reserve inventory
- Authorize payment
- Create shipping label
- On success, orchestrator marks Completed and emits OrderConfirmed.
- On failure at any step, orchestrator triggers compensations in reverse order.
Pseudo-code (orchestrator):
saga = create_saga(orderId)
try:
resvId = cmd("inventory", "/reservations", order)
payId = cmd("payments", "/authorizations", order)
shipId = cmd("shipping", "/labels", order)
complete(saga)
except StepError as e:
compensate_safely([
("shipping", f"/labels/{shipId}/cancel"),
("payments", f"/authorizations/{payId}/void"),
("inventory", f"/reservations/{resvId}/release"),
])
fail(saga, e)
Choreographed Flow
- Order Service emits OrderCreated{sagaId, orderId}.
- Inventory Service consumes and emits InventoryReserved or InventoryRejected.
- Payment Service consumes InventoryReserved and emits PaymentAuthorized or PaymentDeclined.
- Shipping Service consumes PaymentAuthorized and emits LabelCreated.
- If any negative event is emitted, services listening for it trigger their compensations.
Event schemas (JSON):
{
"eventId": "ulid",
"sagaId": "ulid",
"type": "InventoryReserved",
"orderId": "...",
"reservationId": "...",
"occurredAt": "2026-05-06T12:34:56Z"
}
Idempotency and Safe Retries
- Assign deterministic resource IDs from the client or orchestrator (e.g., reservationId = hash(sagaId + sku)).
- Make commands PUT‑like where possible. Example: PUT /payments/authorizations/{authId} with a request body that can be retried safely.
- Store and return the same response for the same Idempotency-Key for a configurable retention window (e.g., 24–72 hours).
Server‑side idempotency skeleton:
CREATE TABLE idempotency (
key TEXT PRIMARY KEY,
response JSONB,
status_code INT,
created_at TIMESTAMPTZ DEFAULT now()
);
if cache := get_idempotent(request.key):
return cache
resp = process()
save_idempotent(request.key, resp)
return resp
Handling Non‑Compensatable Steps
Not all actions are reversible (e.g., sending an email, external bank transfer). Strategies:
- Reorder steps to place irreversible actions last.
- Use Try‑Confirm/Cancel (TCC):
- Try: provisional hold (authorize payment, hold inventory)
- Confirm: finalize when saga is ready to commit
- Cancel: release holds on failure or timeout
- Human‑in‑the‑loop: route to a manual queue for reconciliation.
Concurrency, Isolation, and Invariants
Maintain invariants without distributed locks:
- Unique constraints: prevent double reservation by placing a unique index on (orderId, sku) or business keys.
- Monotonic state transitions: enforce allowed transitions with check constraints or application logic.
- Optimistic concurrency: version rows; reject stale updates; retry with idempotency.
- Quotas via reservations: move from “subtract on commit” to “reserve then confirm/cancel.”
Observability for Sagas
- Tracing: propagate W3C Trace Context across services; add sagaId as a span attribute.
- Logging: structured logs with sagaId, step, attempt, and outcome.
- Metrics: counters for starts, successes, compensations; histograms for step latency; gauges for in‑flight sagas; alert on timeouts and DLQ backlog.
- Audit: append‑only event store or outbox tables for replay and forensics.
Reliability Engineering Tactics
- Timeouts: set per step and saga; use watchdogs to detect stuck instances.
- Circuit breakers: fail fast on unhealthy dependencies; trigger compensation.
- Bulkheading: partition resources per service to avoid cascading failures.
- Retry policies: bounded retries with exponential backoff and jitter; stop retrying when compensation succeeds.
- Exactly‑once illusions: accept at‑least‑once; achieve “effectively once” with idempotency and dedupe logs.
Security and Governance
- Least privilege: each service account can only perform the specific commands and compensations it owns.
- AuthZ context: include principal and scopes in events where necessary; avoid leaking PII.
- Tamper resistance: sign events or use broker features like server‑side encryption and ACLs.
- Compliance: retain saga logs per policy; redact sensitive fields at the edge.
Testing Sagas
- Contract tests: verify commands and events per consumer expectations.
- Property‑based tests: randomize failure points and assert invariants (e.g., stock never negative).
- Deterministic replays: rebuild saga state from stored events/outbox.
- Chaos experiments: inject message duplication, reordering, and partitions.
Common Anti‑Patterns
- Implicit compensations: “we’ll figure it out later.” Write them down and test them.
- Global locks: single global mutex kills throughput; prefer data‑level constraints.
- Silent failures: no DLQ or alerts; issues surface only as customer complaints.
- Over‑synchronous design: blocking HTTP chains create tight coupling and brownouts.
Migration Path from a Monolith
- Identify a business workflow and carve steps with natural compensations.
- Introduce an outbox and events inside the monolith first.
- Extract a service at a time; keep the saga flow stable.
- Add observability and SLIs before scale.
A Minimal Checklist
- Have you defined compensations for every step?
- Are all commands idempotent with keys and deterministic IDs?
- Do you persist saga state and correlate logs/traces by sagaId?
- Are timeouts, retries, and DLQs configured and monitored?
- Can you replay or audit a saga end‑to‑end?
Conclusion
Sagas trade atomicity for availability and scale, but they demand discipline: precise APIs, durable state, reliable messaging, and rich observability. With the right design—idempotent commands, explicit compensations, and a clear choice between orchestration and choreography—you can run business‑critical workflows safely across distributed services without resorting to heavyweight distributed transactions.
Related Posts
Designing resilient REST API webhook retry mechanisms
Design reliable webhook retries: backoff with jitter, idempotency, Retry-After, DLQs, security, and ops patterns for resilient REST API webhooks.

Designing Resilient APIs with the Circuit Breaker Pattern
Learn how the API circuit breaker pattern prevents cascading failures, with design choices, observability, and code examples in Java, .NET, Node.js, and Python.
Webhooks vs Polling APIs: How to Choose, Design, and Operate
Webhooks vs polling APIs: compare latency, cost, scalability, reliability, security, patterns, and code examples—with a practical decision framework.