AI Fraud Detection API Integration: Architecture, Security, and Implementation Guide
Practical guide to AI fraud detection API integration: architecture, payloads, security, thresholds, MLOps, and operations with code samples.
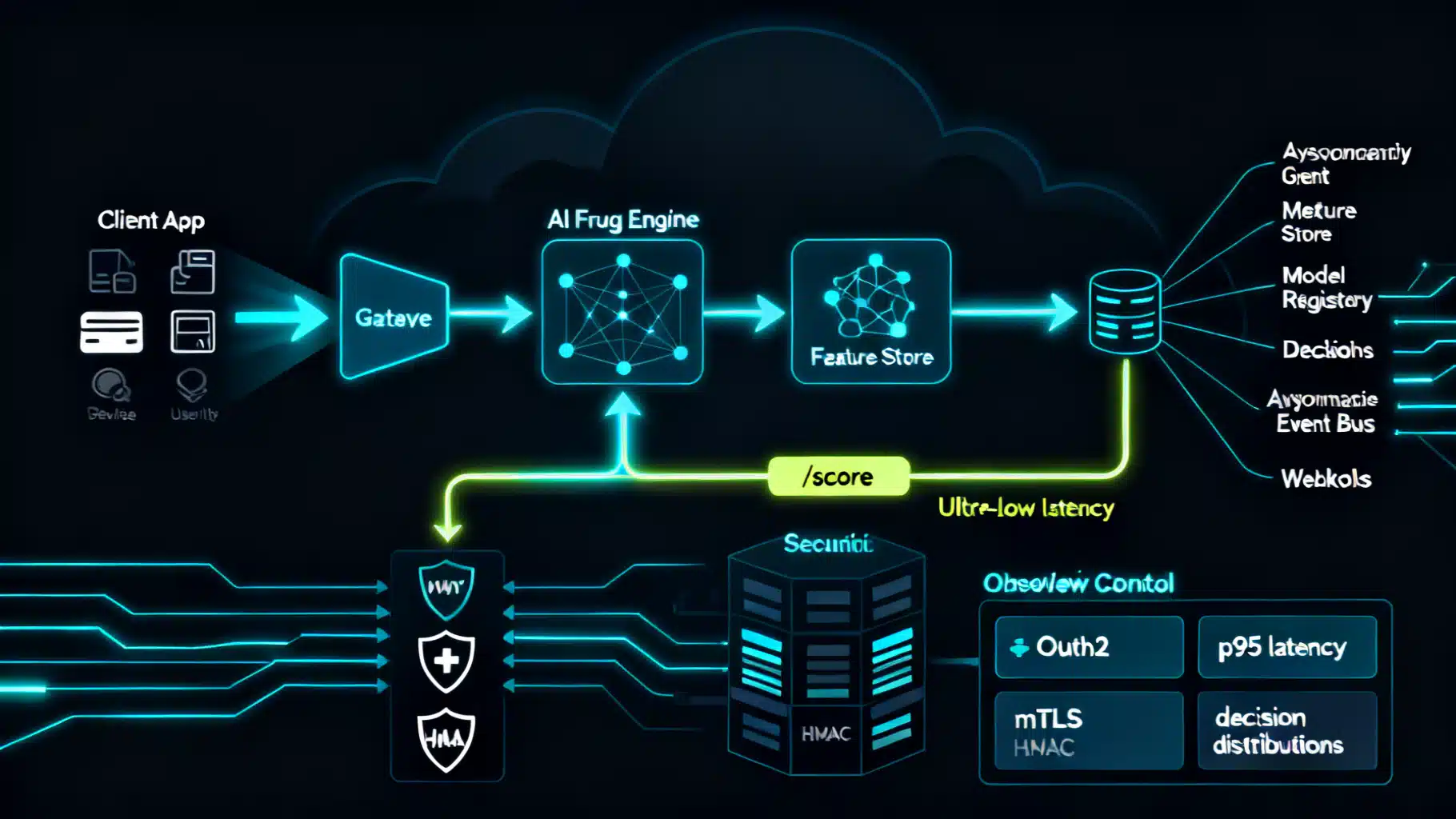
Image used for representation purposes only.
Overview
AI-driven fraud detection is now table stakes for payments, fintech, marketplaces, and subscription platforms. An effective integration does more than post a transaction to a model—it streamlines data flows, secures sensitive context, enforces consistent decisions, and creates feedback loops that keep models current against evolving fraud tactics. This guide walks through an end-to-end integration: architecture patterns, payload design, security, decisioning, MLOps, and operations—with code samples you can adapt.
Core objectives and KPIs
Before writing code, align on measurable outcomes:
- Reduce chargeback rate and fraud loss per $1,000 processed.
- Increase approval rate while keeping false positives within budget.
- Minimize manual review rate and average review handle time.
- Meet SLOs: p95 latency (e.g., <150 ms for scoring), uptime, and decision freshness (model version recency).
System architecture patterns
There are three dominant patterns. Many teams use a hybrid:
- Real-time synchronous scoring
- Flow: App → Fraud API /score → Decision → Checkout/Auth continues.
- Pros: Instant decisioning for block/allow/step-up.
- Cons: Tight latency budget, needs high availability.
- Event-driven async with webhooks/queues
- Flow: App emits events to a bus (e.g., orders, logins). Fraud service scores async and posts decisions to a webhook or stream.
- Pros: Scales with traffic, resilient to spikes; great for continuous monitoring.
- Cons: Not suitable when you must block inline.
- Batch scoring
- Flow: Periodic jobs score historical or pending items (e.g., ledger sweeps).
- Pros: Cost-effective, good for re-scores and model backfills.
- Cons: Not for real-time gates.
Recommended hybrid: Real-time for high-risk checkpoints (account creation, login, payment authorization) plus event-driven enrichment and post-decision monitoring.
Data model and features
High-signal inputs include:
- Identity: email_hash, phone_hash, document IDs (tokenized), name consistency.
- Device and network: device_id, user_agent, OS, IP, ASN, proxy/VPN/Tor indicators, velocity from IP/device.
- Payment: BIN, funding_source, card_issuer_country, AVS/CVV, wallet tokens.
- Behavioral biometrics: typing cadence, pointer path entropy, session length.
- Graph context: shared devices, addresses, emails; distance to known bad clusters.
- Merchant/order: amount, currency, SKU risk, shipping vs billing mismatch.
Use a feature store to standardize transformations for both training and serving. For PII, tokenize or hash with keyed HMAC; never log raw sensitive fields. Enforce deterministic normalization (time zones, country codes, casing).
API surface and versioning
Expose a minimal, well-typed surface:
- POST /v1/score — synchronous scoring and decisioning.
- POST /v1/events — append behavioral/ledger events to profiles.
- POST /v1/labels — ingest outcomes (chargebacks, confirmed fraud, true positives/negatives).
- Webhooks: /v1/webhooks/decision and /v1/webhooks/score_failed.
Versioning: prefix URIs (/v1), maintain schema evolution with additive fields, and deprecate with sunset headers. Use idempotency keys for write endpoints to avoid duplicates on retries.
Example: /v1/score request
{
"idempotency_key": "9b6d2f0e-1fd8-4d2d-8d37-6a6f0d1a5e73",
"event_type": "payment_authorization",
"occurred_at": "2026-05-09T17:21:55Z",
"actor": {
"user_id": "u_12345",
"email_hash": "sha256:...",
"phone_hash": "sha256:..."
},
"payment": {
"amount": 129.99,
"currency": "USD",
"bin": "411111",
"avs_result": "Y",
"cvv_result": "M"
},
"network": {
"ip": "203.0.113.45",
"user_agent": "Mozilla/5.0 ...",
"device_id": "d_7af9...",
"accept_language": "en-US"
},
"order": {
"merchant_id": "m_789",
"shipping_address_hash": "sha256:...",
"billing_address_hash": "sha256:...",
"items": [
{"sku": "sku-abc", "qty": 1, "category": "electronics"}
]
},
"context": {
"session_id": "s_001",
"attempt_number": 2,
"previous_decisions": ["step_up"]
}
}
Example: /v1/score response
{
"request_id": "req_5b3...",
"decision": "allow",
"risk_score": 0.23,
"thresholds": {"block": 0.80, "review": 0.60},
"reasons": [
{"code": "DEVICE_TRUST_LOW", "weight": 0.18},
{"code": "VELOCITY_NORMAL", "weight": -0.12}
],
"model_version": "fraud_gbdt_2026-04-28_17-03",
"explanations": {
"top_features": [
{"name": "ip_risk_score", "contribution": 0.11},
{"name": "account_age_days", "contribution": -0.08}
]
},
"sla": {"p95_latency_ms": 120},
"ttl_seconds": 900
}
Security and compliance
- Authentication: Prefer OAuth2 client credentials or mTLS. If using API keys, pair with HMAC request signatures and strict rotation.
- Transport: TLS 1.2+; pin certificates for outbound webhook consumers where feasible.
- Request signing: Sign the raw body + timestamp header to prevent replay.
- Data protection: Encrypt at rest; segregate encryption keys via a key management service.
- Least privilege: Separate service accounts for scoring, labeling, and analytics.
- Privacy and compliance: Map data flows for PCI-related fields; honor data subject requests; minimize retention (e.g., 13 months for chargeback windows plus a short buffer). Tokenize PII for logs and analytics.
HMAC signature header example
X-Timestamp: 2026-05-09T17:21:55Z
X-Signature: v1=hex(hmac_sha256(secret, timestamp + "." + raw_body))
Implementation step-by-step
- Define the fraud taxonomy and outcomes: ATO, NAF, card testing, triangulation, refund/promo abuse, friendly fraud, mule accounts.
- Map decision points: signup, login, password reset, payment auth, payout, address change.
- Draft schemas and assign owners for each field; mark PII and sensitive categories.
- Implement client SDK wrappers with timeouts (e.g., 300 ms), retries (2–3 with exponential backoff and jitter), and circuit breakers.
- Integrate synchronous /score where you need hard gates; fall back to allow with step-up if the fraud service is unavailable and risk allows it.
- Emit events to /events for behavior streams (logins, device bindings, email updates).
- Implement webhooks for decisions and failures; verify signatures and use replay protection.
- Add labels ingestion (/labels) from chargebacks, manual review tools, and confirmed-good outcomes.
- Run shadow mode (no-op decisions) and A/B canary until metrics stabilize; then ramp.
Minimal cURL smoke test
curl -X POST https://api.fraud.example.com/v1/score \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-H "Idempotency-Key: 9b6d2f0e-1fd8-4d2d-8d37-6a6f0d1a5e73" \
-d @score_request.json
Python example (requests)
import os, time, hmac, hashlib, requests
API_URL = "https://api.fraud.example.com/v1/score"
SECRET = os.environ["FRAUD_HMAC_SECRET"].encode()
def sign(ts, body):
msg = f"{ts}.{body}".encode()
return hmac.new(SECRET, msg, hashlib.sha256).hexdigest()
def score(payload):
body = json.dumps(payload, separators=(",", ":"))
ts = time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime())
headers = {
"Authorization": f"Bearer {os.environ['FRAUD_TOKEN']}",
"Content-Type": "application/json",
"X-Timestamp": ts,
"X-Signature": f"v1={sign(ts, body)}",
"Idempotency-Key": payload["idempotency_key"],
"User-Agent": "fraud-client/1.0"
}
for attempt in range(3):
try:
r = requests.post(API_URL, data=body, headers=headers, timeout=0.3)
if r.status_code in (429, 500, 503):
time.sleep(min(0.05 * (2 ** attempt), 0.4))
continue
r.raise_for_status()
return r.json()
except requests.RequestException:
if attempt == 2:
raise
time.sleep(0.1 * (2 ** attempt))
Node.js example (fetch)
import crypto from 'crypto';
function sign(ts, body, secret){
return crypto.createHmac('sha256', secret).update(ts + '.' + body).digest('hex');
}
Decisioning: thresholds, actions, and cost
- Combine rules + ML: rules for hard business constraints (e.g., embargoed countries), ML for nuanced risk.
- Calibrate scores: Use Platt scaling or isotonic regression; target stable precision at operating points.
- Optimize thresholds to business value: Maximize expected profit, not AUC. Incorporate costs: false positive (lost margin + LTV), false negative (chargeback + fees), review cost, step-up friction.
- Actions by band:
- Low risk: allow + issue trust cookies.
- Medium risk: step-up (3DS, OTP, doc verification) or send to manual review.
- High risk: block + capture telemetry for model improvements.
Labels, feedback, and delay handling
Fraud outcomes are delayed (e.g., chargebacks 30–90 days). Build:
- Label broker: accepts /labels with outcome_type, occurred_at, external_ids.
- Matching rules: deterministic joins via idempotency_key + payment reference.
- Weighting: handle delayed positives via time-decay or importance weights.
- Human-in-the-loop: reviewers provide structured reasons and dispositions; loop these back as high-quality labels.
Webhook: label ingestion (example)
{
"event": "chargeback.created",
"occurred_at": "2026-06-15T10:03:12Z",
"reference": {"payment_id": "pay_123", "idempotency_key": "9b6d..."},
"details": {"reason_code": "4837", "amount": 129.99, "currency": "USD"}
}
Modeling and MLOps essentials
- Class imbalance: use focal/weighted loss; be cautious with SMOTE to avoid leakage.
- Feature leakage checks: no post-transaction info in training features.
- Evaluation metrics: PR-AUC, ROC-AUC, precision@k, recall@threshold, expected value per decision.
- Drift monitoring: population stability index (PSI), feature distribution tests, score calibration drift.
- Online monitoring: alignment between training and serving transforms; track null/NaN rates, feature freshness.
- Model registry and CI/CD: immutable versions, staged rollouts (shadow → canary → ramp), automatic rollback on SLO breach.
- Explainability: expose top contributors per decision to debug and to aid compliance.
Graph and behavioral techniques
Fraud rings exploit shared infrastructure. Add graph signals:
- Connected components from device/email/address overlaps.
- Risk propagation via community detection; compute risk centrality.
- Optional: Graph neural networks (GNNs) for link-based embeddings feeding downstream models.
Observability and runbooks
- Metrics: p50/p95/p99 latency, error rate, saturation (CPU/memory), request volume, decision mix (allow/review/block), approval rate, manual review rate.
- Tracing: instrument client and server spans for /score and webhook delivery.
- Logging: structured, PII-minimized; include request_id, idempotency_key, model_version, decision.
- Dashboards: per-tenant and global; alert on latency SLOs, queue backlog, score distribution shifts.
- Runbooks: timeouts → degrade to step-up; model outage → freeze decisions at conservative thresholds; webhook failure → retry with exponential backoff and dead-letter queues.
Performance and protocols
- Serialization: JSON for ease; Avro/Protobuf for stricter schemas and smaller payloads; consider gRPC for sub-50 ms budgets.
- Caching: short TTL caches for device/IP intelligence; validate stale-on-error to preserve availability.
- Idempotency: dedupe on idempotency_key + event_type.
- Rate limits: document per-tenant limits and backoff headers.
Multi-tenant SaaS considerations
- Tenant isolation: per-tenant encryption keys and namespaces; avoid cross-tenant data leakage in features and logs.
- Noisy neighbor: fairness in rate limits and resource quotas.
- Configuration as data: per-tenant thresholds, rules, and actions stored centrally with audit trails.
Testing strategy
- Sandbox: deterministically seeded responses for edge cases (e.g., missing AVS, high device risk).
- Replay framework: sample production events (tokenized) to test new models.
- Shadow mode: score in parallel; compare decisions without impacting customers.
- A/B and canary: expose increments (approval lift vs. fraud loss) with confidence intervals.
- Adversarial testing: simulate bot traffic, proxy farms, card testing bursts, and refund abuse workflows.
Common pitfalls
- Training-serving skew from inconsistent feature logic.
- Leaky features that use post-decision data.
- Over-reliance on a single signal (e.g., IP risk) that adversaries can rotate.
- No label feedback, leading to model drift and stale thresholds.
- Missing idempotency and webhook verification, causing duplicates or spoofed events.
Deployment checklist
- Security: OAuth2 or mTLS; request signing; key rotation; strict CORS for browser calls.
- Reliability: retries with jitter; circuit breakers; idempotency; backpressure.
- Data: feature store; PII tokenization; retention policies; lineage.
- Observability: metrics, traces, structured logs, audit trails; dashboards for decision mix and calibration drift.
- Governance: model registry, documentation/model card, approval workflow, rollback plan.
- Business: threshold tuning playbook; manual review guidelines; feedback SLAs with payment ops.
Conclusion
A robust AI fraud detection API integration aligns data, security, and decisioning under tight latency and reliability constraints. By designing clean schemas, protecting sensitive context, tuning thresholds to business value, and closing the feedback loop with labels and monitoring, you can raise approval rates and curb losses—even as fraud tactics evolve. Start with synchronous scoring at critical checkpoints, layer in event-driven enrichment, and invest early in observability and MLOps to keep your defenses adaptive.
Related Posts
Designing a Robust AI Customer Support Chatbot Architecture
A practical blueprint for building scalable, safe AI support chatbots—from NLU and RAG to orchestration, guardrails, and observability.

Integrating an AI Writing Assistant via API: Architecture, Code, and Best Practices
A practical guide to integrating an AI writing assistant via API—architecture, prompt design, code samples, safety, evaluation, and performance optimization.

AI Image Generation API Integration: Architecture, Code Examples, and Best Practices
A practical guide to integrating AI image generation APIs with production-ready code, architecture patterns, safety, and cost optimization.