Designing Robust Multi‑Turn Conversational AI: Architecture, Memory, and Evaluation
A practical guide to multi‑turn conversational AI: architecture, memory, grounding, safety, and evaluation patterns for reliable, scalable assistants.
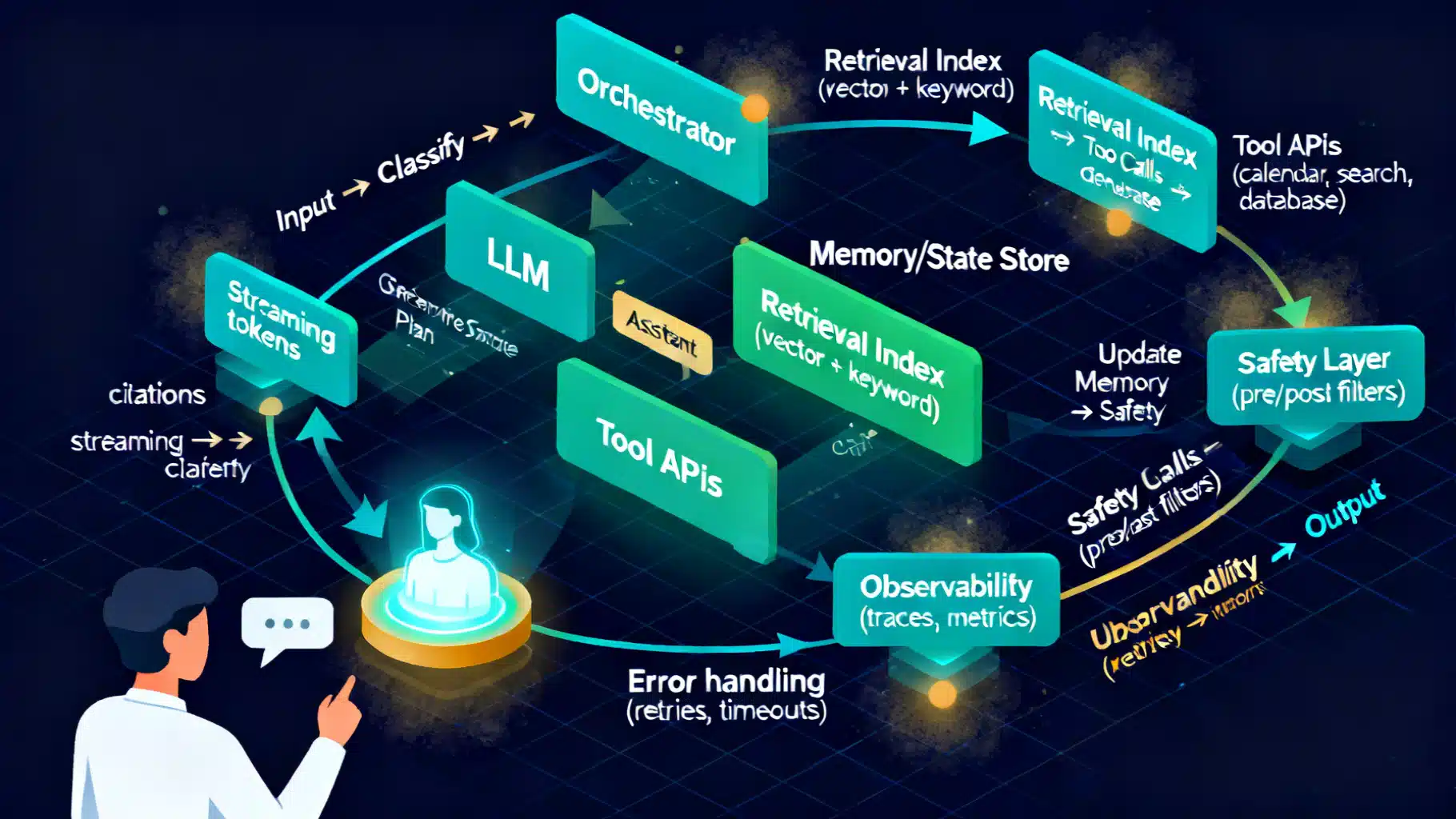
Image used for representation purposes only.
Why Multi‑Turn Matters
Single‑shot chat feels magical, but real work happens across turns: clarifying goals, negotiating constraints, verifying results, and adapting as context changes. Multi‑turn design elevates an assistant from a text generator to a collaborative problem‑solver. It also introduces hard problems—state tracking, grounding, safety, latency, evaluation—that don’t show up in one‑off prompts. This article distills proven patterns for building robust multi‑turn systems.
Reference Architecture
A pragmatic stack separates concerns so each turn is reliable and auditable:
- Client UX: chat UI, voice, or API; streaming tokens and partial UI updates.
- Orchestrator: routes turns, maintains conversation state, chooses tools, enforces policies.
- Model Layer: LLM(s) and smaller classifiers (intent, safety, language ID, toxicity, PII).
- Memory/State: short‑term turn buffer, distilled summaries, user profile/preferences.
- Grounding: retrieval (vector + keyword), structured data, function/tool calling.
- Safety/Compliance: input and output filters, policy runtime, red‑team probes.
- Observability: traces, cost/time budgeter, evaluation hooks, replay.
A canonical turn looks like this:
- Receive user event (text/speech/API).
- Validate and classify (lang, intent, safety, domain).
- Expand context from state store and retrievers.
- Plan: decide to ask, retrieve, or act via tools.
- Execute tools; collect structured results.
- Generate grounded response with citations or UI actions.
- Update memory; log telemetry; schedule follow‑ups if needed.
Conversation State and Memory
State is more than a transcript. Treat it as layered memory with explicit lifecycles:
- Turn Buffer: N most recent messages; optimized for immediacy; aggressively pruned.
- Conversational Summary: distilled objectives, decisions, unresolved questions.
- Working Memory: task‑specific slots (dates, constraints, entities, identifiers).
- User Profile: stable preferences and permissions (opt‑in, revocable, auditable).
- External Facts: retrieved snippets with provenance and timestamps.
Design state as typed objects, not free text. Example schema:
{
"conversation_id": "c_123",
"turn": 42,
"summary": "User is planning a 3-day trip to Denver in July; prefers hiking.",
"goals": ["book lodging under $200/night", "find 2 hikes < 8 miles"],
"slots": {
"destination": "Denver",
"start_date": "2026-07-11",
"nights": 3,
"budget_per_night": 200
},
"profile": {"currency": "USD", "units": "imperial", "access": ["calendar"]},
"facts": [
{"source": "docs", "id": "v-889", "title": "Trail A", "timestamp": "2026-05-10"}
]
}
Key practices:
- Separation of concerns: keep “what was said” distinct from “what we believe.”
- Explicit uncertainty: represent confidence scores or nulls; don’t hallucinate values.
- Forgetting policy: summarize and purge; cap retention windows; honor user deletion requests.
Context Management at Scale
Context windows are finite. Use layered distillation to maintain relevance:
- Recency Window: the last K turns that materially affect the next step.
- Rolling Summary: periodic compression into bullet points or structured frames.
- Topic Buckets: maintain multiple mini‑summaries per topic/task to avoid cross‑contamination.
- Retrieval‑as‑Join: instead of stuffing, fetch just‑in‑time facts with filters (topic, time, persona).
A summarizer should be deterministic and schema‑constrained. Example pseudo‑contract:
{
"input": {"last_turns": ["..."], "previous_summary": "..."},
"output_schema": {
"goals": ["string"],
"decisions": ["string"],
"open_questions": ["string"],
"entities": [{"name": "string", "type": "string", "value": "string"}]
}
}
Grounding and Tool Use
Grounding combats drift and hallucinations. Combine plan‑then‑act with function calling:
- Tool Catalog: typed functions with auth, rate limits, idempotency keys, and cost tags.
- Planner: decides which tools to call and in what order; emits rationale internally but never exposes raw chain‑of‑thought to users.
- Executor: runs tools; handles retries, timeouts, and partial failures.
- Response Generator: cites sources, formats results, and proposes next steps.
Design tools for clarity and safety:
- Short, well‑typed inputs/outputs; avoid free‑form blobs.
- Safe defaults and guardrails; enforce required parameters in the orchestrator.
- Deterministic error messages the model can learn to recover from.
Example tool spec:
{
"name": "search_hotels",
"description": "Find hotels with availability.",
"input": {"city": "string", "start_date": "date", "nights": "int", "max_price": "number"},
"output": {
"results": [
{"id": "string", "name": "string", "price": "number", "currency": "string", "url": "string"}
]
},
"idempotency_key": "${city}-${start_date}-${nights}-${max_price}",
"timeout_ms": 4000
}
Dialogue Policy and Turn‑Taking
Even with powerful LLMs, a lightweight policy improves control:
- Initiative Management: when to ask, when to act, when to summarize.
- Ask‑Confirm‑Act Loop: propose plan → confirm critical assumptions → execute.
- Progressive Disclosure: collect parameters incrementally; avoid overwhelming the user.
- Mixed‑Initiative Handoffs: allow the user to interrupt or redirect at any time.
A simple policy table can map conversation states to strategies:
- Unknown goal → ask clarifying question.
- Known goal, missing slots → targeted slot questions.
- All slots present → propose plan and confirm.
- Confirmed → act with tools and report back with citations.
Managing Uncertainty and Repair
Great assistants admit doubt and recover quickly:
- Calibrated Language: “I’m not certain about X; would you prefer A or B?”
- Hypothesis Lists: offer 2–3 options rather than open‑ended guesses.
- Repair Moves: reflect, restate, and correct when contradicted by tools.
- Transparent Limits: communicate freshness limits, coverage gaps, and fallback paths.
Personalization, Consent, and Privacy
Personalization boosts efficiency but must be explicit and reversible:
- Consent UX: make profile memory opt‑in with clear scopes and retention windows.
- Data Minimization: store only what you need; prefer derived preferences to raw PII.
- User Controls: “forget this,” “export,” “pause memory,” “why was this suggested?”
- On‑Device or Edge Memory for sensitive contexts; encrypt at rest and in transit.
Safety and Policy Guardrails
Layer defenses so no single control bears all risk:
- Pre‑Filters: language ID, NSFW/abuse detection, malware/PII screens.
- Policy Engine: block/allow/transform with reasons; keep a remediated version for the model.
- Model‑in‑the‑Loop Safety: instruction tuning for refusals and safer completions.
- Post‑Filters: scan model output before display or tool invocation.
- Adversarial Testing: jailbreak suites, perturbation tests, and ongoing red teaming.
Multimodal and Real‑Time Considerations
Voice and vision add constraints:
- Streaming ASR + partial NLU for low‑latency prompts; support barge‑in and turn taking via silence or keyword.
- Incremental Rendering: show draft answers quickly; refine as tools return.
- Visual Grounding: reference on‑screen elements; maintain a UI state graph.
Reliability, Latency, and Cost
Production systems must be economical and resilient:
- Budgets per turn: tokens, time, dollars; degrade gracefully under pressure.
- Caching: memoize retrieval and tool responses by idempotency key; apply TTLs.
- Retries with Jitter: exponential backoff; circuit breakers for flaky providers.
- Shadow and Canary: try new prompts/policies with a fraction of live traffic.
- Observability: traces with spans for classification, retrieval, tools, and generation.
Evaluation: From Turns to Journeys
Measure what matters at conversation scale, not just model perplexity:
- Task Success Rate (TSR): was the user’s goal achieved within constraints?
- Turns to Success: how many exchanges did it take?
- Clarification Quality: did questions reduce ambiguity and rework?
- Grounding Rate: proportion of claims with verifiable evidence.
- Safety Violations and Intervention Rate.
- User‑Reported Satisfaction and Trust.
Build an evaluation loop:
- Create scenario libraries with gold goals and constraints.
- Simulate users (scripted + probabilistic) to cover happy paths and edge cases.
- Human review for subjective qualities (tone, helpfulness, safety).
- Regression gates in CI: block deploys on metric regressions.
Prompting and Orchestration Patterns
A few durable patterns for multi‑turn control:
- System + Developer Instructions: stable guardrails separate from user content.
- Schema‑Driven Outputs: JSON‑only modes for plans, tool inputs, and summaries.
- Retrieval‑Augmented Generation (RAG): cite sources; prefer extract‑then‑compose.
- Planner‑Executor: small prompt for planning; separate prompt for final user text.
- Self‑Verification: lightweight re‑ask phase where the model checks critical claims against tools before responding.
Common Failure Modes and Fixes
- Topic Drift: use topic buckets and constrain retrieval scope.
- Over‑Asking: cap consecutive clarification turns; summarize and propose defaults.
- Hallucinated Tools/Results: whitelist tools; validate outputs against JSON schema.
- Infinite Loops: include a step counter and watchdog; surface graceful failure.
- Privacy Leaks: strip PII from logs; synthetic data for pre‑prod.
Minimal Orchestrator Flow (Pseudocode)
async def handle_turn(event):
safety = prefilter(event.text)
if safety.blocked: return apologize(safety.reason)
cls = classify(event)
state = load_state(event.conversation_id)
context = build_context(state, event)
plan = plan_turn(context, tools=CATALOG)
results = []
for step in plan.steps:
out = await call_tool(step) if step.type == 'tool' else None
results.append(out)
if step.critical and out is None:
return repair_question(step)
reply = generate_reply(context, plan, results)
post = postfilter(reply)
update_state(state, event, plan, results, post)
log_metrics(event, state, plan, results, post)
return post
Launch Checklist
- Clear objectives and success metrics per use case.
- Tool catalog with auth, quotas, and observability.
- Guardrails and refusal policies validated by red teaming.
- Memory policy: what persists, for how long, and how users control it.
- Evaluation harness with scenario coverage; CI gates.
- Incident playbooks and rollback mechanisms.
Roadmap: What’s Next
- Hierarchical planners that decompose multi‑session projects.
- Memory that learns over time while preserving privacy via differential privacy or on‑device profiles.
- Multimodal context that joins screen, voice, and environment sensors.
- Agentic collaboration: multiple specialized agents coordinated by a supervisor with clear guarantees.
Takeaway
Design multi‑turn assistants like resilient software systems: explicit state, grounded actions, layered safety, and continuous evaluation. When in doubt, ask concise clarifying questions, propose a plan, act with verifiable tools, and summarize decisions so the next turn starts ahead—not from scratch.
Related Posts

The Essential Guide to Evaluating Retrieval‑Augmented Generation: Metrics that Matter
A practical, end-to-end guide to RAG evaluation metrics—from retrieval and grounding to faithfulness, relevance, and online impact.

LLM Fine-Tuning Dataset Preparation: An End-to-End Guide
A step-by-step guide to preparing high-quality datasets for LLM fine-tuning, from sourcing and cleaning to formats, safety, splits, and evaluation.
Function Calling vs. Tool Use in LLMs: Architecture, Trade-offs, and Patterns
A practical guide to function calling vs. tool use in LLMs: architectures, trade-offs, design patterns, reliability, security, and evaluation.