Designing a Robust REST API Response Envelope: Patterns, Pitfalls, and Practical Examples
A practical guide to the REST API response envelope pattern: design, errors, pagination, performance tips, and when to use or skip it.
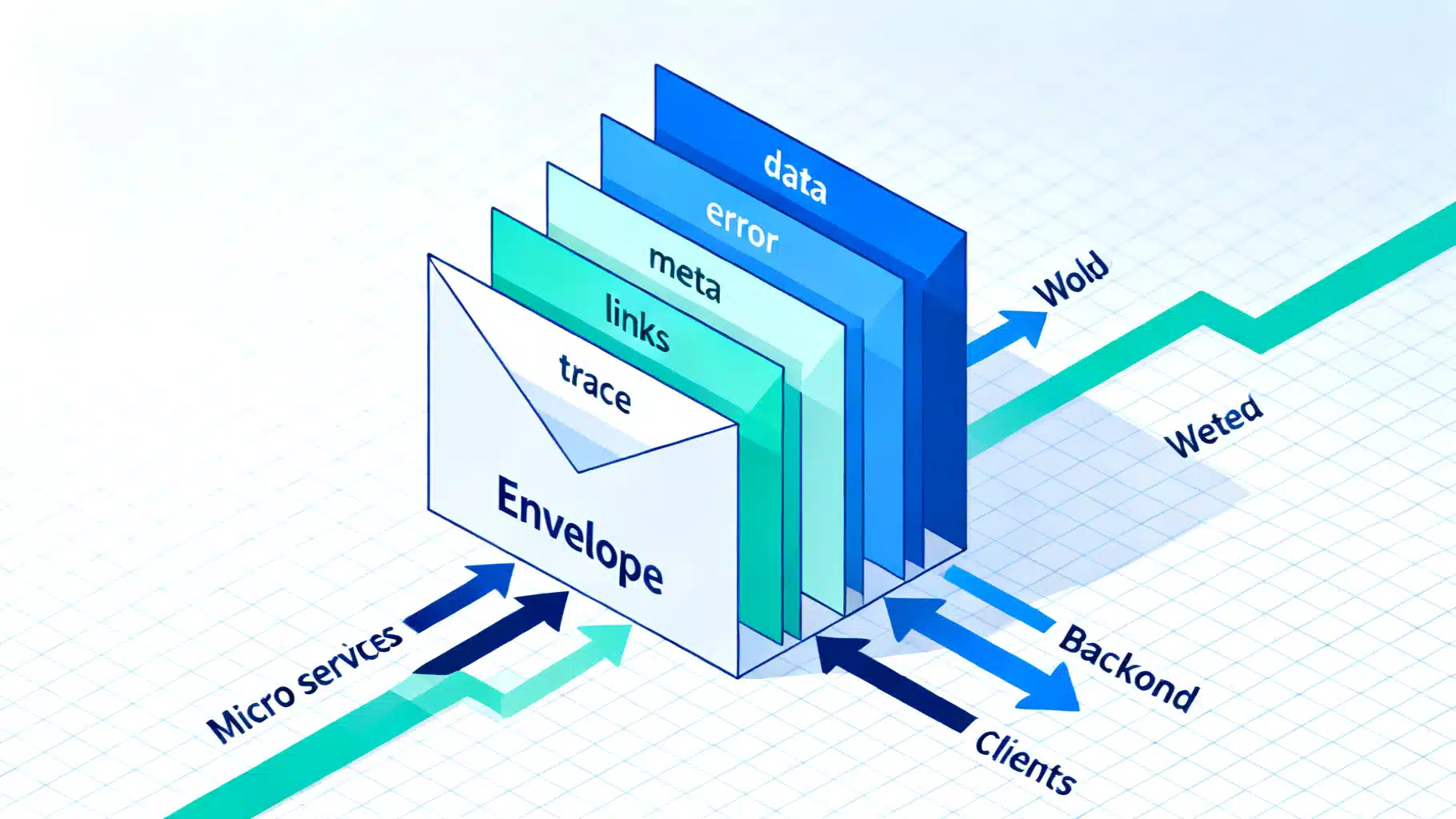
Image used for representation purposes only.
Overview
The response envelope pattern wraps every REST response in a predictable, top‑level structure. Instead of returning a raw resource—or a raw error—your API returns a consistent object that always contains fields for the primary payload, metadata, and error information. The goal is to improve client ergonomics, simplify documentation, and make room for cross‑cutting concerns like tracing, pagination, and feature flags without breaking existing consumers.
This article explains when and how to use response envelopes, the trade‑offs involved, and concrete patterns you can adopt in production.
What is a Response Envelope?
A response envelope is a stable outer JSON object that frames the variable content of a response.
Common shape:
{
"data": { /* resource(s) */ },
"error": null,
"meta": { /* non-resource info */ },
"links": { /* HATEOAS or pagination */ },
"trace": { /* correlation IDs, timings */ }
}
- data: The primary payload—an object, array, or null.
- error: A structured error object when a problem occurs; null on success.
- meta: Non-resource information (paging cursors, totals, rate-limit counts, processing hints).
- links: Navigational or pagination links (self, next, prev).
- trace: Correlation IDs, request duration, and service provenance.
Why Use It?
- Consistency: Clients parse the same shape regardless of endpoint or status code.
- Evolvability: You can add non-breaking fields in meta, links, or trace without changing resource schemas.
- Clear error contracts: A consistent error object beats ad hoc strings or varying structures.
- Pagination and counts: Add totals/cursors without cluttering resource models.
- Observability: Surface correlation IDs and timing for easier debugging.
- Partial success: Represent batch results cleanly (some items succeed, some fail) without inventing new ad hoc formats.
Trade‑offs and When Not to Use It
- Verbosity and size: Additional nesting increases payload size; consider compression.
- Redundancy with HTTP semantics: If misused, envelopes can obscure HTTP status codes. Keep status codes meaningful.
- Caching complexity: If trace or volatile meta changes per request, cache keys may fragment. Separate cache‑sensitive and volatile fields.
- Not always necessary: For extremely simple, internal services or when using GraphQL/gRPC, an explicit envelope may be redundant. For streaming (SSE, WebSockets), prefer event frames rather than a single envelope.
Recommended Envelope Design
Start with a small, stable core:
{
"data": {},
"error": null,
"meta": {
"request_id": "8e6f…",
"limit": 25,
"remaining": 247,
"duration_ms": 12
},
"links": {
"self": "/v1/orders?limit=25",
"next": "/v1/orders?cursor=eyJvZmZzZXQiOjI1fQ"
},
"trace": {
"correlation_id": "0b7c…",
"service": "orders-api"
}
}
Guidelines:
- Keep field names short, unambiguous, and stable.
- Make error mutually exclusive with data in success cases; prefer error = null when status < 400.
- Use HTTP status codes accurately (200, 201, 204, 400, 404, 409, 500). The envelope complements, it does not replace, HTTP semantics.
- Use camelCase or snake_case consistently; align with your org standards.
- Reserve names for future use to avoid collisions (for example, do not overload meta for resource attributes).
Error Handling
Adopt a structured error object compatible with Problem Details (RFC 7807) while fitting your envelope.
Example error response (HTTP 409 Conflict):
{
"data": null,
"error": {
"type": "https://api.example.com/errors/conflict",
"title": "Conflict",
"status": 409,
"code": "ORDER_ALREADY_EXISTS",
"detail": "Order with id 123 already exists.",
"instance": "/v1/orders/123",
"violations": []
},
"meta": {
"request_id": "f3a2…",
"duration_ms": 7
},
"links": {
"self": "/v1/orders/123"
},
"trace": {
"correlation_id": "c5af…"
}
}
For validation errors (HTTP 422 Unprocessable Entity), include a violations array:
{
"data": null,
"error": {
"type": "https://api.example.com/errors/validation",
"title": "Validation failed",
"status": 422,
"code": "VALIDATION_ERROR",
"detail": "One or more fields are invalid.",
"violations": [
{ "field": "email", "rule": "format", "message": "Must be a valid email" },
{ "field": "age", "rule": ">=18", "message": "Must be at least 18" }
]
},
"meta": { "request_id": "c1de…" },
"links": { "self": "/v1/users" },
"trace": { "correlation_id": "4bc1…" }
}
Lists, Pagination, and Counts
For collections, keep resource arrays inside data.items and place counts/cursors in meta. Prefer cursor‑based pagination for scalability.
{
"data": {
"items": [ { "id": "o1" }, { "id": "o2" } ]
},
"error": null,
"meta": {
"count": 2,
"total": 137,
"cursor": "eyJvZmZzZXQiOjJ9",
"limit": 2
},
"links": {
"self": "/v1/orders?limit=2",
"next": "/v1/orders?cursor=eyJvZmZzZXQiOjJ9"
},
"trace": { "correlation_id": "8a77…" }
}
Best practices:
- Put totals behind an opt‑in (e.g., include=total) if they’re expensive to compute.
- Keep cursors opaque; never expose internal IDs directly.
- Return 206 Partial Content only for ranged responses; normal pagination still uses 200.
Partial Success for Batch Operations
Some endpoints (bulk create, bulk delete) benefit from explicit partial success modeling.
{
"data": {
"succeeded": [ { "id": "a1" }, { "id": "a3" } ],
"failed": [
{
"input": { "id": "a2" },
"error": { "code": "DUPLICATE", "detail": "Already exists" }
}
]
},
"error": null,
"meta": { "request_id": "b0df…" },
"links": { "self": "/v1/assets/bulk" },
"trace": { "correlation_id": "ef22…" }
}
Return HTTP 207 Multi‑Status or 200 depending on your policy; document it clearly.
Interplay with HTTP Caching and ETags
- Include ETag/Last‑Modified headers to enable caching independent of envelope content.
- Avoid placing volatile fields (e.g., request_id, duration_ms) in ways that cause downstream caches to vary; use response headers for per‑request diagnostics if necessary.
- Consider a slim envelope for highly cacheable endpoints: expose trace in headers (X‑Request‑Id, X‑Correlation‑Id) and keep meta stable.
Security and Privacy Considerations
- Do not leak internals (stack traces, SQL errors) in error.detail. Use a stable error code plus a supportable message.
- Treat correlation IDs as non‑sensitive but avoid embedding user PII in meta or trace.
- Rate‑limit information is helpful but can assist attackers; consider scoping or coarsening counts.
Versioning and Backward Compatibility
- Prefer additive changes inside meta, links, and trace; clients should ignore unknown fields.
- For breaking changes to data schemas, version at the URL or via content negotiation (e.g., application/vnd.example.v2+json).
- Document the envelope as part of your API contract so client SDKs can rely on it.
Implementation Examples
Node.js (Express) Middleware
// envelope.js
function sendEnvelope(res, {
status = 200,
data = null,
error = null,
meta = {},
links = {},
trace = {}
} = {}) {
const requestId = res.locals.requestId;
const body = {
data,
error,
meta: { request_id: requestId, ...meta },
links,
trace: { correlation_id: requestId, ...trace }
};
return res.status(status).json(body);
}
module.exports = { sendEnvelope };
Usage in a route:
app.get('/v1/orders/:id', async (req, res, next) => {
try {
const order = await repo.get(req.params.id);
if (!order) return sendEnvelope(res, { status: 404, error: {
type: 'https://api.example.com/errors/not-found',
title: 'Not Found', status: 404, code: 'NOT_FOUND',
detail: `Order ${req.params.id} not found`
}});
return sendEnvelope(res, { status: 200, data: order });
} catch (e) { next(e); }
});
Java (Spring Boot)
// Envelope.java
public class Envelope<T> {
public T data;
public ErrorBody error;
public Map<String, Object> meta = new HashMap<>();
public Map<String, String> links = new HashMap<>();
public Map<String, Object> trace = new HashMap<>();
}
public class ErrorBody {
public String type;
public String title;
public int status;
public String code;
public String detail;
public List<Map<String, Object>> violations = new ArrayList<>();
}
// Controller
@GetMapping("/v1/orders/{id}")
public ResponseEntity<Envelope<Order>> get(@PathVariable String id) {
Envelope<Order> env = new Envelope<>();
Optional<Order> order = repo.findById(id);
if (order.isEmpty()) {
env.error = new ErrorBody();
env.error.title = "Not Found";
env.error.status = 404;
env.error.code = "NOT_FOUND";
env.error.detail = "Order " + id + " not found";
return ResponseEntity.status(404).body(env);
}
env.data = order.get();
return ResponseEntity.ok(env);
}
Documenting with OpenAPI
Define a reusable schema for the envelope and compose resource types into data via generics or oneOf/allOf patterns.
components:
schemas:
Envelope:
type: object
properties:
data: {}
error:
$ref: '#/components/schemas/ErrorBody'
meta:
type: object
additionalProperties: true
links:
type: object
additionalProperties: { type: string }
trace:
type: object
additionalProperties: true
required: [data, error]
ErrorBody:
type: object
properties:
type: { type: string, format: uri }
title: { type: string }
status: { type: integer }
code: { type: string }
detail: { type: string }
violations:
type: array
items:
type: object
additionalProperties: true
For each endpoint, set data to the appropriate schema using allOf:
responses:
'200':
description: OK
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/Envelope'
- type: object
properties:
data:
$ref: '#/components/schemas/Order'
Performance Tips
- Enable gzip/br compression; envelopes compress well.
- Support sparse fieldsets (fields=) to limit payload size of data.
- Support includes/expansion flags to avoid N+1 calls while keeping envelopes compact.
- Consider omitting empty optional sections (e.g., links when none) to cut bytes; document this behavior.
Migration Strategy
If you’re adding envelopes to an existing API:
- Introduce them in a new version (e.g., /v2) to avoid breaking legacy clients.
- Provide SDK adapters that map legacy shapes into the envelope.
- Run dual‑write/dual‑read in staging to validate metrics and caching behavior.
- Communicate cutover timelines and offer sample code and tests.
When an Envelope Shines vs. When to Skip
Use an envelope when:
- You need consistent error semantics across teams.
- You plan to add pagination/metadata without breaking clients.
- You operate multiple microservices and want uniform observability.
Skip or minimize it when:
- Payloads are tiny and internal, and HTTP semantics alone suffice.
- You’re using GraphQL/gRPC where the protocol already defines a framing structure.
- Ultra‑low latency + large volume responses are sensitive to even small overheads; consider headers for meta instead.
A Practical Checklist
- Return correct HTTP status; do not hide everything behind 200.
- Keep error and data mutually exclusive on success.
- Stabilize field names: data, error, meta, links, trace.
- Use opaque cursors and optional totals.
- Put per‑request diagnostics in headers or a trace object; avoid cache fragmentation.
- Document the envelope in OpenAPI and ship contract tests.
- Make clients resilient to unknown fields.
Conclusion
The response envelope pattern gives your REST API a durable contract and space to evolve. By standardizing data, error, meta, links, and trace, you simplify client logic, gain room for critical cross‑cutting concerns, and reduce accidental breaking changes. Adopt it thoughtfully—preserving HTTP semantics, watching cache keys, and documenting the contract—and it will pay dividends as your API surface grows.
Related Posts
Standardizing REST API Responses: A Practical Guide with Examples
A practical guide to standardizing REST API responses—status codes, envelopes, errors, pagination, headers, and examples to build resilient, consistent APIs.
REST API Content Negotiation: A Practical Guide
Design, implement, and test REST API content negotiation: headers, q-values, media types, versioning, caching, and error handling with practical examples.
Designing REST API Batch Operations: Patterns, Semantics, and Examples
Designing robust REST API batch operations: models, atomicity, idempotency, error handling, async jobs, limits, and examples.