Designing a Real-Time AI Translation API: Architecture, Protocols, and Code
Design and implement a low-latency real-time AI translation API: architecture, protocols, latency budgets, security, and production-ready code examples.
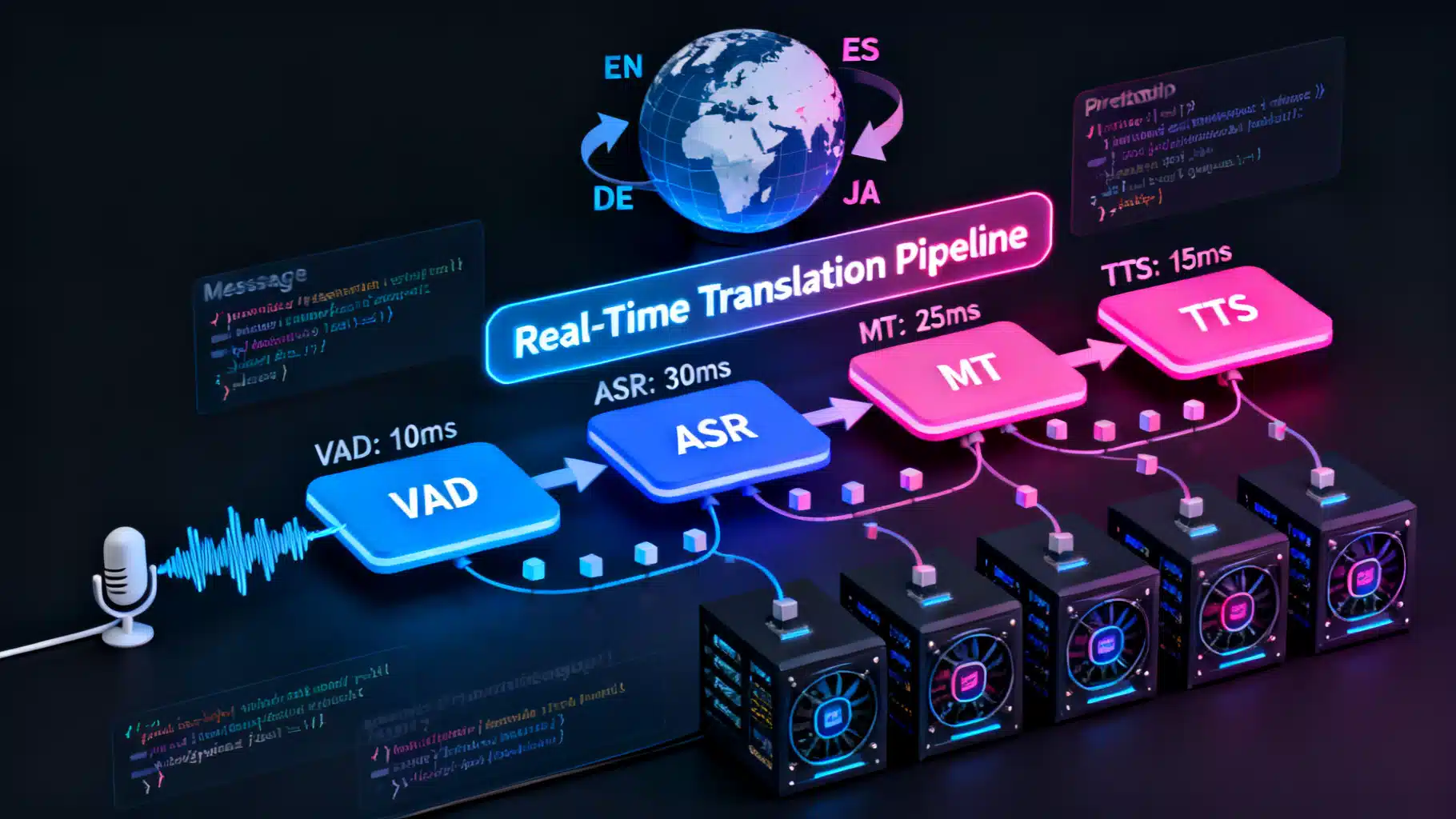
Image used for representation purposes only.
Overview
Real-time AI translation APIs turn live speech or text in one language into another language in milliseconds. Unlike batch translation, which waits for entire documents or recordings, real-time systems stream partial results as input arrives. This enables live captions, multilingual voice chat, customer support handoffs, cross-language conferencing, and in-product assistance.
In this article, we’ll design a production-grade real-time translation API end-to-end: architecture, protocol choices, latency budgets, schemas, reliability, security, and cost. We’ll also include code snippets you can adapt today.
Core Pipeline Architecture
Most real-time translation stacks follow a three-stage pipeline, sometimes with shortcuts when the input is text-only:
- Voice Activity Detection (VAD): Detects speech start/stop and segments audio into frames.
- ASR (Automatic Speech Recognition): Converts audio frames to source-language text. Incremental decoding streams partial words.
- MT (Machine Translation): Translates partial or finalized source text to the target language. Supports adaptive dictionaries and domain terms.
- TTS (Text-to-Speech, optional): Synthesizes translated speech. Streams phonemes or audio chunks for low-latency playback.
Supporting systems include language identification, punctuation and casing models, diarization (who spoke), profanity/PII masking, and alignment for subtitles.
Text-only simultaneous translation
If the input is text (e.g., chat), you can skip ASR/TTS. For “simultaneous” translation, use incremental decoding and policies like wait-k (translate after k source tokens) to trade latency for quality.
Protocol Options for Streaming
Real-time experiences need bi-directional, low-latency channels. Common transports:
- WebSocket: Widely supported in browsers; simple framing with JSON or binary. Great for text and audio chunk streaming.
- gRPC (HTTP/2): Bi-directional streaming with protobuf schemas; strong typing and efficient on mobile/servers.
- WebRTC: Ideal for browser-to-browser or NAT-traversed audio/video with built-in jitter buffers; use the DataChannel for control messages.
- Server-Sent Events (SSE): One-way server-to-client updates; fine for partial translations if input is sent by another channel.
Guidance:
- For web apps: WebSocket or WebRTC. Use WebRTC if you already handle media streams and need NAT traversal.
- For native/mobile: gRPC streaming for efficiency and schema rigor.
- For simple demos: WebSocket + JSON messages.
Message Model and Schemas
Design clear, versioned message types. A minimal WebSocket schema might include:
{
"type": "hello",
"version": "2026-05-01",
"session": {
"source_lang": "es",
"target_lang": "en",
"tts_voice": "en-US-female-1",
"features": ["vad", "partial_results"]
}
}
Input messages:
- input_audio: PCM16LE or Opus frames, base64 or binary.
- input_text: UTF-8 text segments.
- control: pause/resume, set_target_lang, set_dictionary, commit (force segment end), ping.
{ "type": "input_audio", "seq": 12, "format": "pcm16le", "sample_rate": 16000, "data": "<base64>" }
{ "type": "input_text", "seq": 33, "text": "¿Cómo estás?" }
{ "type": "control", "action": "commit" }
Server outputs:
- partial_asr, final_asr
- partial_translation, final_translation
- tts_audio (optional)
- error
{ "type": "partial_asr", "seq": 12, "text": "hola a to…" }
{ "type": "final_asr", "seq": 12, "text": "hola a todos" }
{ "type": "partial_translation","seq": 12, "text": "hello eve…" }
{ "type": "final_translation", "seq": 12, "text": "hello everyone" }
{ "type": "tts_audio", "seq": 12, "format": "opus", "data": "<base64>" }
Version the protocol and keep message types backward compatible. Use a heartbeat (ping/pong) for liveness and to estimate RTT.
Latency Budget and How to Hit It
Real-time translation feels natural when end-to-end median latency stays below 300–700 ms (domain-dependent). Break down the budget:
- Capture: 20–50 ms (frame size, audio encoding)
- Uplink network: 20–80 ms (RTT/2)
- ASR decode: 50–150 ms (incremental)
- MT inference: 20–120 ms (depends on model size and context)
- TTS chunk: 50–200 ms
- Downlink network: 20–80 ms
Optimization tactics:
- Smaller frames (20–30 ms) and immediate send; enable VAD to avoid silence.
- Incremental ASR with partial hypotheses; set aggressive endpointing.
- MT with speculative decoding and wait-k; cache translation of common n-grams.
- TTS that streams phonemes/audio in 50–100 ms chunks. Prewarm voices.
- Compress audio with Opus at 16–24 kbps; use TCP_NODELAY or tuned gRPC keepalives.
- Co-locate compute with users (multi-region) and enable autoscaling with warm pools.
Quality, Evaluation, and Policies
Measure both quality and timeliness:
- Quality: COMET/BLEURT/chrF for offline evaluation; human QA for critical domains.
- Timeliness: Average Lagging, Segment Delay (first-byte and final), Word Error Rate for ASR.
- Policies: domain glossaries, style guides, formality, and profanity masking.
Support developer controls:
- target_lang, formality=casual/formal, punctuation=on/off
- dictionary: { “source”: “AcmeCloud”, “target”: “AcmeCloud” }
- stabilization=aggressive|balanced|fast for partial updates.
Error Handling and Backpressure
Design for the unhappy path:
- Retries with idempotent seq numbers.
- Backpressure via server “drain” signals and client-side rate limiting.
- Jitter buffer to smooth bursty network delivery.
- Timeouts: close sessions after N seconds of silence.
- Graceful degradation: if TTS fails, continue text captions.
- Structured errors:
{ "type": "error", "code": "RATE_LIMIT", "retry_after_ms": 5000, "message": "Too many concurrent streams." }
Security and Privacy
- TLS everywhere; pin modern ciphers. Use short-lived OAuth 2.0 or signed HMAC tokens.
- PII handling: optional redaction on logs; configurable data retention with default deletion.
- Customer-managed keys for stored artifacts; S3-style object encryption for recordings.
- Enable on-device or edge inference for sensitive workloads; avoid storing raw audio by default.
- Compliance: document data flows; support DPA, SOC 2, GDPR deletion endpoints, and HIPAA-eligible deployments when needed.
Cost and Scalability
- GPUs: pick architectures supporting mixed precision; run ASR/MT/TTS on shared pools.
- Batching: micro-batch MT/TTS at 10–30 ms windows without hurting latency.
- Model size tiers: small (fast) vs large (accurate); switch dynamically based on SLOs.
- Autoscaling: maintain a warm pool to cover p95 spikes; cold starts kill first-token latency.
- Pricing model: per-minute audio + per-million MT tokens + TTS minutes; include egress.
A quick back-of-envelope:
- 60 seconds of 16 kHz mono PCM ≈ 1.9 MB raw; with Opus at 20 kbps ≈ 150 KB.
- GPU inference cost often dwarfs bandwidth; prioritize model efficiency and batching.
REST for Batch, Streaming for Real Time
Expose both:
- REST for synchronous text translation and short clips.
- WebSocket/gRPC streaming for live sessions.
Example: REST Text Translation
curl -X POST https://api.example.com/v1/translate \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{
"source_lang": "de",
"target_lang": "en",
"text": "Guten Morgen! Wie geht es Ihnen?",
"dictionary": {"Guten Morgen": "Good morning"},
"formality": "formal"
}'
Response:
{ "translation": "Good morning! How are you?", "latency_ms": 87 }
Example: WebSocket Streaming (Node.js client)
import WebSocket from 'ws';
import fs from 'fs';
const ws = new WebSocket('wss://api.example.com/v1/realtime?target_lang=en', {
headers: { Authorization: `Bearer ${process.env.TOKEN}` }
});
ws.on('open', () => {
ws.send(JSON.stringify({ type: 'hello', version: '2026-05-01', session: { source_lang: 'es', target_lang: 'en', features: ['partial_results', 'vad'] }}));
const stream = fs.createReadStream('sample-es.pcm');
stream.on('data', chunk => {
ws.send(JSON.stringify({ type: 'input_audio', format: 'pcm16le', sample_rate: 16000, data: chunk.toString('base64') }));
});
stream.on('end', () => ws.send(JSON.stringify({ type: 'control', action: 'commit' })));
});
ws.on('message', msg => {
const m = JSON.parse(msg.toString());
if (m.type === 'partial_translation') process.stdout.write(`\r${m.text}`);
if (m.type === 'final_translation') console.log(`\nFinal: ${m.text}`);
if (m.type === 'tts_audio') {/* play or buffer audio */}
});
Example: gRPC Proto for Bi-Directional Streaming
syntax = "proto3";
package realtime.v1;
message SessionConfig {
string source_lang = 1;
string target_lang = 2;
bool partial_results = 3;
}
message ClientMessage {
oneof payload {
SessionConfig hello = 1;
AudioChunk audio = 2;
TextChunk text = 3;
Control control = 4;
}
}
message AudioChunk { bytes data = 1; string format = 2; int32 sample_rate = 3; }
message TextChunk { string text = 1; }
message Control { string action = 1; }
message ServerMessage {
oneof payload {
AsrResult asr = 1;
TranslationResult translation = 2;
TtsChunk tts = 3;
Error error = 4;
}
}
message AsrResult { bool final = 1; string text = 2; }
message TranslationResult { bool final = 1; string text = 2; }
message TtsChunk { bytes data = 1; string format = 2; }
message Error { string code = 1; string message = 2; }
service RealtimeTranslate {
rpc Stream (stream ClientMessage) returns (stream ServerMessage);
}
Server Considerations
- Session state: per-connection buffers, language settings, user dictionary, and rate limits.
- Threading: separate IO loop from inference; use queues between ASR→MT→TTS.
- Prioritization: prefer recent frames; drop stale partials when backlogged.
- Observability: emit spans for ASR, MT, TTS; tag with session_id and region.
Minimal Python server skeleton (FastAPI + WebSockets)
from fastapi import FastAPI, WebSocket
import asyncio, base64
app = FastAPI()
@app.websocket('/v1/realtime')
async def realtime(ws: WebSocket):
await ws.accept()
session = { 'source_lang': 'auto', 'target_lang': 'en' }
try:
while True:
msg = await ws.receive_json()
t = msg.get('type')
if t == 'hello':
session.update(msg.get('session', {}))
elif t == 'input_audio':
pcm = base64.b64decode(msg['data'])
# asr_partial = asr_decode_incremental(pcm)
await ws.send_json({ 'type': 'partial_asr', 'text': 'hola a to…' })
# translation = mt_translate(asr_partial, session['target_lang'])
await ws.send_json({ 'type': 'partial_translation', 'text': 'hello eve…' })
elif t == 'control' and msg.get('action') == 'commit':
await ws.send_json({ 'type': 'final_translation', 'text': 'hello everyone' })
except Exception:
await ws.close()
Note: Replace stubs with real models/pipelines and production-grade error handling, auth, and limits.
Dictionaries, Formatting, and Stabilization
- User dictionaries: exact matches and protected terms; apply before MT post-editing.
- Formatting: keep numbers, dates, measurement units; convert punctuation and casing correctly.
- Stabilization: control how often partial outputs revise earlier words. Offer:
- fast: minimal buffering, frequent revisions
- balanced: small buffer, fewer revisions
- aggressive: larger buffer, more stable subtitles
Testing, SLOs, and Monitoring
- Golden sets per domain (support, medical, legal) with source audio/text and expected translations.
- Measure p50/p95 latency for first-token and final output; track revision rate for partials.
- Alerts: ASR WER drift, MT COMET drop, TTS glitch rate, and GPU queue depth.
- Tracing: one span per stage; propagate session and request IDs.
- Canaries: shard a small percent to new models; compare online metrics before rollout.
Deployment Patterns
- Multi-region, active-active with sticky sessions to keep context local.
- Edge media relays or TURN for WebRTC; terminate TLS close to users.
- Blue/green for model updates; ensure vocabulary snapshots are versioned.
Build vs. Buy Checklist
Consider buying if:
- You need coverage for 100+ languages with premium voices and you’re time-constrained.
- Compliance or uptime guarantees are contract-critical.
Consider building if:
- Ultra-low-latency, on-prem, or air‑gapped requirements.
- Deep domain adaptation and proprietary dictionaries.
- Cost leverage at scale or custom languages/voices.
Criteria to evaluate vendors:
- Latency under load, revision rate of partials, domain glossary support, per-language WER/COMET, TTS naturalness, logging controls, and egress fees.
Developer Checklist
- Choose transport (WebSocket/gRPC/WebRTC) and define a stable schema.
- Target a median end-to-end latency budget; instrument every stage.
- Implement VAD, incremental ASR, wait-k MT, and streaming TTS.
- Add dictionaries, profanity/PII masking, and stabilization controls.
- Harden with auth, rate limits, backpressure, and structured errors.
- Ship with golden tests, tracing, and SLO dashboards.
Conclusion
A real-time translation API is more than a single model—it’s a carefully engineered pipeline, transport, and developer experience. With the right message schemas, latency discipline, and observability, you can deliver natural, multilingual conversations that scale from prototypes to global production.
Related Posts

AI Speech-to-Text API Comparison: A Practical Buyer’s Guide and Benchmarking Blueprint
A buyer’s guide to AI speech-to-text APIs: how to compare accuracy, latency, privacy, cost, and run your own benchmarks—without vendor hype.

The Price of “Free” in 2026: Big Platforms Redraw the Lines
YouTube’s ad-block crackdown, Prime Video’s pricier ad‑free tier, and ads in ChatGPT: 2026 is redefining what “free” online really means.
Designing a Robust AI Customer Support Chatbot Architecture
A practical blueprint for building scalable, safe AI support chatbots—from NLU and RAG to orchestration, guardrails, and observability.